Howdy, Stranger!
Categories
- 3K All Categories
- 152 Research & Reading
- 692 The Zettelkasten Method
- 8 Knowledge Work
- 100 Writing
- 464 Software & Gadgets
- 154 Workflows
- 730 The Archive
- 15 Plug-In Showcase
- 88 Resolved Issues
- 225 Projects Logs and Journals
- 83 Project: Zettelkasten.de
- 53 Critique my Zettel
- 171 Random
- 373 Introduce Yourselves!
Comments
Yeah, absolutely agree. I support this standard, I was just curious if it was easy to enable my laziness.
Next question, also maybe not your problem: Do you know of any way to stop all of my photos taken from my phone showing up in landscape rather than portrait? Sometimes when I'm reading I'll take a photo of the page to transcribe later, and it's harder to read sideways.
EDIT: As per this Stack Overflow, it has to do with the EXIF data, and that's not something that we're gonna solve with a ST plugin, I don't think. The simple solution is to open the image in preview and save it again, and ST loads it fine.
That's what I was going to suggest: Open in preview, cmd+r until good and save. SublimeText just loads the image and not the hint in the EXIF to rotate it
Turns out the advanced tag search was not that advanced after all. It needed to be advanced a bit further
This changes the syntax a bit, so the TL;DR version is: instead of
use
[^] note the commas.
Why is that? Glad you asked ; time for some
; time for some
News from the README
Advanced Tag Search
To search for more sophisticated tag combinations, use the command
ZK: Search for tag combinationfrom the command palette.It will prompt you for the tags you want to search for and understands quite a powerful syntax; let's walk through it:
Grammar and Syntax
search-spec: search-term [, search-term]* search-term: tag-spec [ tag-spec]* tag-spec: [!]#tag-name[*] tag-name: {any valid tag string}What does that mean?
#tag: matches notes tagged with#tag!#tag: matches all that are not tagged with#tag*asterisk to change the meaning of#tag#tag#tagHow does this work?
Each search is performed in the order the search-terms are specified.
#car, #dieselwill first search for#carand then narrow all#carmatches down to those also containing#diesel.#carAND#diesel.Each tag-spec in a search-term adds to the results of that search-term.
#car #planewill match everything tagged with#carand also everything tagged with#plane#carOR#plane.Each tag-spec can contain an
*asterisk placeholder to make#tag*stand for all tags starting with#tag#tag*and!#tag*.#car*: will match everything that contains tags starting with#car, such as:#car,#car-manufacturer, etc.!#car*: will match all results that do not contain tags starting with#car:#plane #car-manufacturerwill be thrown away#submarinewill be keptPutting it all together
Examples:
#transport !#car: all notes with transport + all notes not containing car (such as#plane)There is no comma. Hence, two search terms will be evaluated and the results of all of them will be combined (OR).
#transport, !#car: all notes with transport - all notes containing carHere, there is a comma. So first all notes tagged with
#transportwill be searched and of those only the ones that are not tagged with#carwill be kept (AND).Pretty powerful.
#transport #car, !#plane:#transportor#carbut never#plane#transport #car !#plane:#transportor#caror anything else that's not#planeI omitted examples using the
*placeholder, it should be pretty obvious.The following screen-shot illustrates the advanced tag search in action:
##AI, !#world*are shown: only one note matches##AIare shown##AI, one of them also tagged with#world-dominationwhich gets eliminated by, !#world*.I agree, get rid of spaces for files you want to use from elsewhere, then you don’t have to replace space characters with
%20to make URLs work.Author at Zettelkasten.de • https://christiantietze.de/
Not sure if anyone else but myself might find this useful, but the TOCs have arrived:
Automatic Table Of Contents
Some notes can get quite long, especially when turning overview notes into growing documents. At some stage it might make sense to introduce a table of contents into the text. This can be useful when using the markdown preview plugin to quickly check your text in a browser.
To insert a table of contents at your current cursor position:
[ctrl]+[shift]+[p](or[cmd]+[shift]+[p]on macOS)zktocZK: Auto-TOCThe table of contents will be placed between two automatically generated comments that also serve as markers for the plugin. It will consist of a bulleted list consisting of links to the headings in your text. The links are only relevant when converting your text into another format, e.g. by using the markdown preview plugin.
Why a bulleted list and not a numbered one? You might have numbered the sections yourself. Numbered lists would get in the way in that case. Also, numbered lists produce
ii.instead of1.2when nesting them.Example before TOC:
Example after TOC:
# 201711250024 Working with tocs tags = #sublime_zk #toc <!-- table of contents (auto) --> * [201711250024 Working with tocs](#201711250024-working-with-tocs) * [This is a very long note!](#this-is-a-very-long-note) * [It contains many headings](#it-contains-many-headings) * [[**with funny chäråcters!]](#with-funny-characters) * [as can duplicate headings](#as-can-duplicate-headings) * [as can duplicate headings](#as-can-duplicate-headings_1) <!-- (end of auto-toc) --> ## This is a very long note! At least we pretend so. ## It contains many headings That's why we are going to need a table of contents. ### [**with funny chäråcters!] Funny characters can be a challenge in the `(#references)`. ## as can duplicate headings # as can duplicate headingsNote: Whenever you need to refresh the table of contents, just repeat the above command.
Note: You can configure the separator used to append a numerical suffix for making references to duplicate headers distinct: by changing the
toc_suffix_separatorin the settings. It is set to an underscore by default (markdown preview, parsers based on Python's markdown module). If you use pandoc, you should set it to-.The following animation shows TOC insertion and refreshing in action:
Automatic Section Numbering
Especially when your text is large enough for needing a table of contents, it might be a good idea to number your sections. This can be done automatically by the plugin as follows:
[ctrl]+[shift]+[p](or[cmd]+[shift]+[p]on macOS)zkZK: Number HeadingsAutomatically inserted section numbers will look like in the following note:
Note: You can refresh the section numbers at any time by repeating the above command.
Note: To switch off numbered sections, use the command
ZK: Remove Heading Numbers.The animation below shows both section (re-)numbering and auto-TOC:
I'm a pedant, so I think section numbering should not be part of the content but the style. It's the job of LaTeX to be configured properly to insert section numbers in PDFs; and it's the HTML converter's job to insert these info into the type-set HTML file. If you insert the numbers in the content file, you do what uneducated Microsoft Word users do: make font big and bold and add number manually instead of use heading level X style. It's training people who use a markup language to act against their best interest which should've brought them to the plain text approach in the first place.
Author at Zettelkasten.de • https://christiantietze.de/
@ctietze I get your points and I don't want to educate people out of good practices or incentivize bad practice.
Yet, I agree with both of us. My motivation for both TOC and section numbers, and also inline image display is personal and probably very special. Sometimes I just don't want to leave the editor and still have a feeling of what the "rendering" would look like. So I display images, I put a TOC in there and I just like numbered sections. No need to call pandoc with
--tocand--number-sections, for instance. Also helps when only a simple markdown processor is at hand. The section numbers can be removed as quickly as they're introduced, so now I completely don't (need to) worry about them. I tend to just put them in when I feel like it and remove them before I save or convert to PDF; except if the text is really sort of final, then I tend to leave them in because I just like numbered sections without having to convert to another format. Having an inline TOC exactly where I want it, is something I really like as well.Initially I wanted the section numbers being displayed as "phantoms", just like images: something one can't edit, so it's clear it's just some sort of optional, view-generated annotation of the text, like the underlines in links in a way -- or even line numbers in the gutter. But the next time I hit alt+m for quick preview I was missing them in the HTML output so I thought it would be handy to just put them into the content. I am glad I did.
With images rendered inline, and section numbers + TOC in the content, I find myself less and less converting the (few) rather lengthy texts to HTML or PDF just for reading them or skimming through them. They look great enough in my editor. I realized this had an additional benefit: I don't switch program / window anymore. No browser window or PDF viewer to close. I just stay in text. No need to generate a preview. No need to close a preview. No need for a live-preview window next to the editor that steals screen estate. In a weird way that feels like a more text-based approach than when I was converting my text into a non-plain-text-format for intermediate consumption.
So where do we draw the line? Is syntax coloring OK? Is stylizing clickable links in the editor OK? Yes, because they don't make it into the content. Now, I view the section numbers as stylizing that makes it into the content. But for a reason: that not-so-well default-configured converters can be used -- or conversion can be skipped altogether -- or "conversion" for preview can be replaced by just turning the numbers on, and turning them off when I would normally close the preview (or a bit later ).
).
Nobody needs to use those features but since I found them handy, I found it OK to share them. I am pro-choice in this case. Using these features is completely optional and can even be discouraged officially. Sometimes "handy" will still win, though, I suppose (does with me).
Inspired by our conversation over here, the plugin has a new setting:
If you set this to
true, then it switches to MultiMarkdown mode when dealing with references.This affects auto-completion of cite-keys: They will show up as
#citekeyin the auto-completion list (as opposed to@citekeyin default pandoc mode).Auto-completed references will look like this:
[][#citkeys].Auto-Bib will look slightly different as well:
As you can see, the bibliography is not hidden inside a comment block anymore.
You can refresh your auto-bibs just by re-running the auto-bib command, after switching to MultiMarkdown, if you so like.
Instead of adding this as a boolean toggle, wouldn't a
citation-styleproperty scale better with the posible values of 'pandoc' (default) and 'mmd'/'multimarkdown' today and possibly future additions?Author at Zettelkasten.de • https://christiantietze.de/
This screenshot just pushed me over the edge!
I decided to put in support for
[[201712011900 Note-Links With Titles]].Unfortunately SublimeText does not like to underline spaces; it looked a bit silly having every word underlined but not the spaces in between. So I opted for just leaving the note ID underlined. In a way that is actually more precise, since it's only the ID that makes the link work; the title is ignored.
Of course, I have a screenshot. Tried it with @Sascha's note. I hope that's OK
Something that's been bugging me for a while:
When using ag, we have the awesome external, persistent search results file. I usually put it in a separate pane. Like, I split my window into 2 columns and have the search results to the right.
When I ctrl+click a note link in there, the linked note also opens up in the right (=active) pane.
So I have "fixed" this now by doing the following: (New/clicked) notes will always open in "group 0" and external search results (tag lists, referencing note lists, tagged notes lists) will always open in group 1. So, regardless if you have a vertical or horizontal split, it will always do the right thing (in most cases).
If you haven't split your window, this will have no effect. It won't auto-split.
If you happen to split your windows in more complicated ways and this behaviour gets in your way, please tell me. I consider making settings for that, so you can chose your default note pane and default results pane. It might appear to be tricky to find out the pane numbers but it should be doable: 0 is the first pane, 1 the one after the 1st split, etc. Trial and error should lead you to the solution. This sounds more cumbersome than it is. But for the moment, there's no setting anyway
To make this pain with panes go away, I made it more user-friendly.
From the README:
Working with Panes
This only applies if you have split your window into multiple panes. By default, notes are opened in the first pane and if you have
aginstalled, search results are opened in the second pane. So in a 2-column layout notes are left and results are right. In a 2-row layout notes are at the top, results at the bottom. Notes are opened when clicking on a note-link or creating a new note, results are displayed by the various search operations, tag list, etc.If you have a more complex layout or you want to change the default target panes, there is a command for you:
[cmd]+[shift]+[p]on macOS ([ctrl]+[shift]+[p]on Windows and Linux).zkto list the Zettelkasten commands.ZK: Select Panes for opening notes/resultsThis will first prompt you for the pane number notes should be opened in and, if you have
aginstalled, it will then prompt you for the pane number results should be opened in.To help you with finding out the pane numbers, it shows a pane identifier inside each pane, reading "Pane n", where n is the pane's number.
The following screenshot illustrates that:
The plugin will remember your choices as long as SublimeText is running. To make these changes permanent, add the following to the plugin's settings:
// Pane where notes are opened when a link is clicked or a new note is created // Pane 0 is the 1st pane ever "pane_for_opening_notes": 0, //Pane where search results and tag lists, etc are opened (if ag is installed) // Pane 1 is the second pane, created when you split the window // in a 2-column layout, this is the right column // in a 2-row layout, this is the bottom row "pane_for_opening_results": 1,Hello, I recently discovered this plugin and I just wanted to tell you it's a pure joy to use. Really smart and it allows a very smooth user experience.
I love the inline image option, but I have a small problem with it in distraction mode. While the text stays centered, the images are aligned to the left.
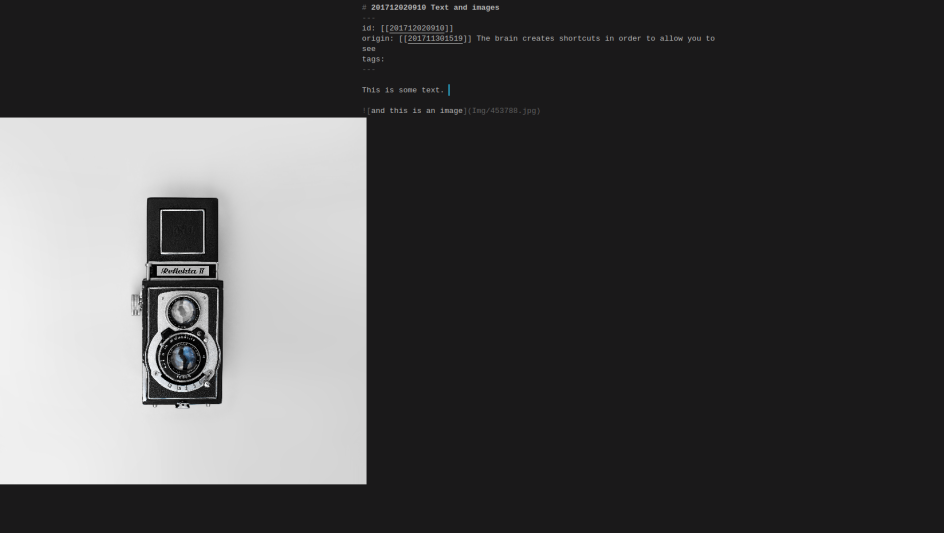
Any ideas on how to solve this?
I was also wondering if you could maybe include this option in the plugin settings, I would love to be able to set it as default.
Thank you.
Thank you! That's very nice to hear!
I had no idea. Distraction-free mode is a ... pain in SublimeText. Turns out the only way to solve this, is:
Distraction Free.sublime-settingshave to be queried forwrap_width.wrap_width-1length.draw_centeredistrueinDistraction Free.sublime-settings--> no surprises for people with left-aligned distraction-free configurations.The plugin now tries to find out if distraction-free mode is on or off by listening to the
toggle_distraction_freecommand. As long as you use the menu or keyboard shortcuts to enable/disable distraction-free, this should work. In distraction free mode the plugin uses the new method to display images, in non-distraction-free mode, it uses the normal way to display them.It also keeps track of which views are currently displaying images, so it can switch image display modes as needed when you switch to distraction-free and back.
There is one draw-back: If you save your note in distraction-free mode and have the setting
trim_trailing_white_space_on_save": true, then the previously appended spaces are deleted and your images move. I might probably be able to fix this by refreshing displayed images after save. But then the modified-indicator would not go away when you save, so it's a bad idea. I recommend, in that case, you just re-run theZK: show imagescommand.That can probably be done like this: If the setting is
truewhen you open a note, it will display images. When you then start modifying your note and delete some or add more images, you have to run theZK: Show Imagescommand to refresh. Would that be fair?[Edit]: Maybe a hack like this could work: Instead of just appending spaces to the line, I could append spaces and a
.dot at the end. That way the line length would be preserved when you save and the plugin would not need to do anything on save.[Edit2]: You can try this yourself. Carefully put a
.at column 79 before showing images. Then show them and save the file.Of course! Thanks for your suggestions! They make the plugin more and more useful
The setting is:
Would inserting non-breaking spaces improve the situation as a hack in comparison to adding a dot
.as content? Both will affect HTML conversion, though, so maybe the dot is better because it's more obvious.Author at Zettelkasten.de • https://christiantietze.de/
Good thinking. It's all a hack...
would be less intrusive in the HTML, consume 6 characters in the markdown source, and look even weirder than a dot. So both have their pros and cons.Hey, what do you think: I could also just expand the closing
):[Edit]: This would only happen if you ever entered distraction-free mode.
That's how I've implemented it now. Until a better hack comes along
Oh, I didn't mean")
but inserting the unicode character directly. But that's rather nonsensical. Your panned-out closing paren seems to work fine and doesn't ruin the MD nor the HTMLAuthor at Zettelkasten.de • https://christiantietze.de/
That was fast
Thank you, sir !
We could be twins...
I am a Zettler
Love the Sublime Zettelkasten! Thx for all the effort you put into making it.
Quick idea => perhaps the ID format should be tweaked a bit
The current format, YYYYMMDDHHMM, creates ID conflicts if you create a few notes in rapid succession (which I sometimes do if Im creating a few notes)!
Ex:
Create three notes a,b,c
# 201712041043 a
# 201712041043 b
# 201712041043 c
And create links to those notes in another note.
If you click the links to b or c, you end up at note a.
Perhaps YYMMDDHHMMSS would be a better solution to avoid these ID clashes? Unless you had quick fingers, it would be hard to create ID conflicts .
.
I feel your pain. Occasionally I am in the same situation. I just want to get 5 things off my mind quickly before I start forgetting them, and create 5 notes quickly -- ending up manually renaming them later.
However, the
YYYYMMDDHHMMformat is a really wise decision and I am hesitant to change it. We are supposed to think before creating a zettel note. Thinking for a minute is not asked for too much, in general.I don't like a situation like this:
Switching to
YYMMDDHHMMSSis possible. But I object due to these reasons -- which might be silly reasons but hang in there for a moment:So I propose another change: Incrementing the minute to the next available minute when you create a new note; in your example:
And even more weird: I would even allow seconds > 59:
After your burst, time will catch up with you pretty soon. I think everybody can live with an ID that's a few minutes off the actual creation time.
That way we can stick to shorter, wiser IDs. We don't need to support IDs of differing lengths. And yet we can rapid-fire when we really need to.
What do you guys think?
I could never settle the argument for myself if, in case of conflict, IDs should be incremented or decremented; the former could cause more conflicts in a minute or two, the latter might fill gaps that are farther in the past than expected, provided you have just created a few notes in the minutes before the conflict. These are even weirder edge cases than quickly creating notes, so I think any consistent solution is a good solution.
Allowing minutes and seconds >59 is weird, because you cannot tranlate them back to date--time-stamps without trouble. Edit: So keeping minutes in the 0--59 range, which is just as complicated an algorithm, is preferable.
Author at Zettelkasten.de • https://christiantietze.de/
Agree w/ avoiding IDs of different lengths.
A cute cute cute way to keep everything at 12 places, and throw in seconds to avoid conflicts =>
Convert HHMMSS into pure seconds and convert to base 24. This works because in base 24, HHMMSS in seconds only needs 4 places:
86400 base 10 (seconds in a day) => 6600 base 24
(I'd use hex, since there is support for it everywhere, but it requires 5 digits to represent 86400 base 10)
So 9:30 PM today in our new format (YYYYMMDD + HHMMSS in seconds converted to base24) would be:
201712045E90
Main drawback is giving up time stamp readability for HHMMSS, which I don't mind.
There are a bunch of cute ways to play w/ bases and unicode symbols if you want to go shorter (make MM a single unicode symbol, but that feels dangerous).
@ctietze thx for your valuable insights. If I had to choose, I'd increment. The future is infinite, the past is not (unless you start filling gaps which is super-weird ). Allowing for minutes up to 99 would add a nice buffer to keep the hours more stable.
). Allowing for minutes up to 99 would add a nice buffer to keep the hours more stable.
But the more I think about it, the more I come to the (quite obvious) conclusion that it's the 12 digits, while remaining a human-parseable timestamp, that's the problem; they just can't handle the specific use case well. The 12 digits are fine under the assumption that one would not create more than 1 note per minute. That assumption gets challenged sometimes - and in the rapid-fire case it looses. It's the assumption that has to be fixed, and consequently, the ID-length. 14-digit IDs might not be so bad after all.
So I figured I could change my
{12}regexes to{12,14}which would also allow for 13-digit timestamps, but I am fine with that.Interesting idea, at least it preserves the date. If I'd have to choose a format that's not meant to be human-interpretable as a timestamp, I'd go for 4-digit hex IDs starting from 0000. Since Luhmann exceeded 0xffff notes, I'd add a 5th digit. New assumption: Nobody creates more than 1 million Zettel notes in their lifetime .
.
I am all for supporting 14-digit note IDs now. Not using them by default, but configurable: binary configurable. Either 12 or 14 ('seconds or not'). No fancy stuff in between. It's meant to be a timestamp.
I am thinking about a command that turns all your 12-digit note-ids into 14-digit ones. I'd replace only 12-digit numbers that match existing note-IDs. But I am almost certain, it won't catch all the use-cases I didn't think of - and might even cause harm in multi-line block-quotes, so I am staying off of it for now.
At some stage one probably just must decide whether a mix of 12-digit and 14-digit notes is OK or whether to rename all notes and fix all links.
I'll try to fix all the regexes and magic number twelves for now...