Tinybase

Just gauging interest...
In the coming weeks I'm considering releasing my hyper-minimal take on Zettelkasten to a wider audience. My rationale has always been to squash complexity in favor of a quick & lightweight method of retrieving notes (nothing at all wrong with other apps that have all the bells & whistles btw). The same codebase runs on any of Windows, Linux, BSD (Apple likely to be included soon as well) with zero issues.
Some screen shots...
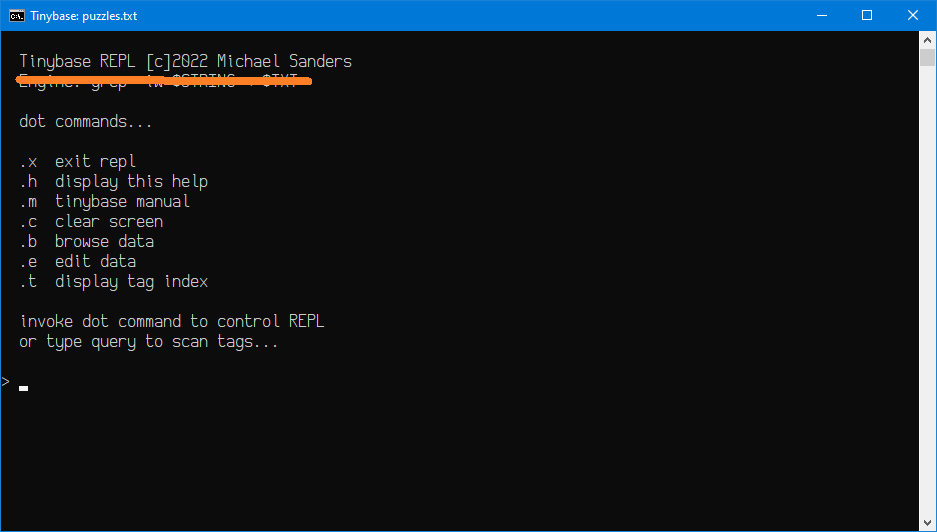
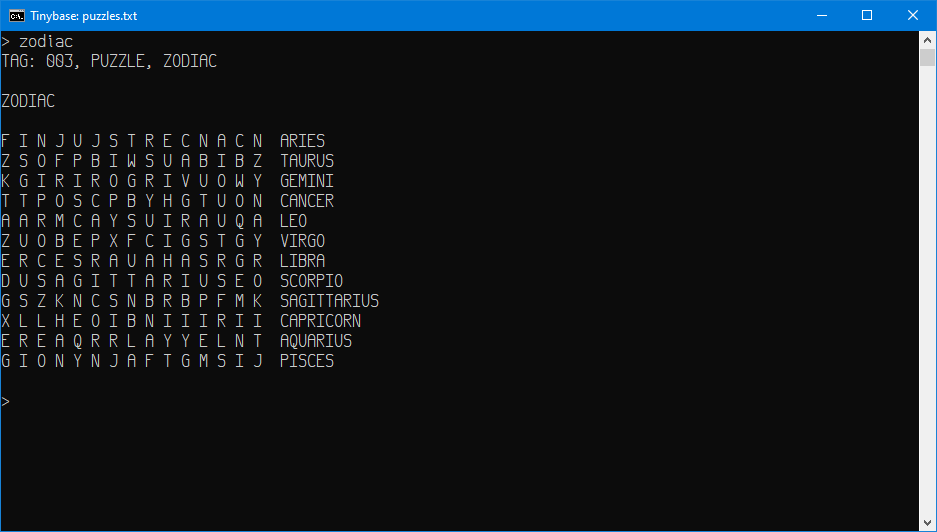
The interface as you noticed is commandline driven & features a REPL (Read Evaluate Print & Loop) to process commands. As it stands now, the source code is merely 27 Kilobytes in size & would be great to toss on a USB drive so your notes are easy to access. No smartphone interface as I'm not much interested in that domain. At any rate, if this sounds like something you might be interested in, check in every now & again & I'll hopefully post a download link eventually.
Howdy, Stranger!
Categories
- 3K All Categories
- 152 Research & Reading
- 692 The Zettelkasten Method
- 7 Knowledge Work
- 99 Writing
- 464 Software & Gadgets
- 154 Workflows
- 729 The Archive
- 15 Plug-In Showcase
- 88 Resolved Issues
- 225 Projects Logs and Journals
- 83 Project: Zettelkasten.de
- 53 Critique my Zettel
- 171 Random
- 373 Introduce Yourselves!
Comments
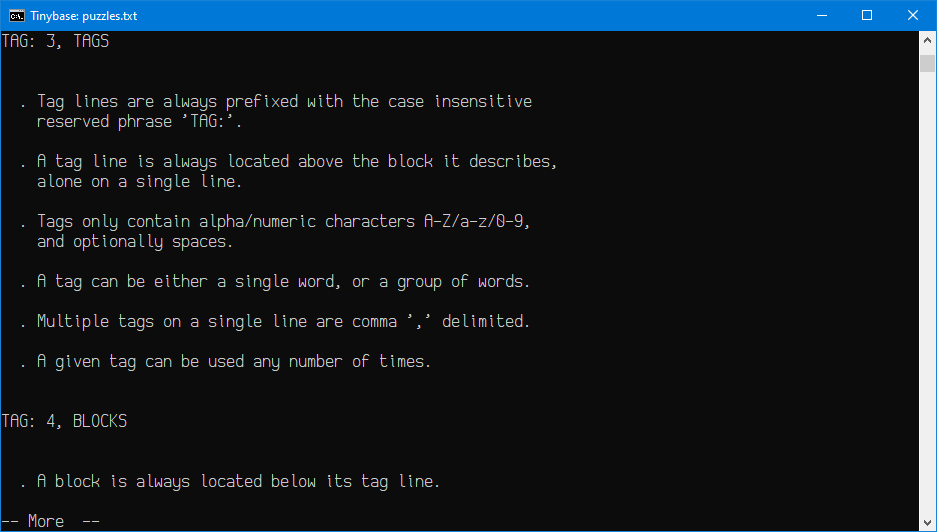
Okay, some great progress the last couple of days (screen shot at end of post - click for full image). Thus far...
compound queries with a single invocation when comma-delimited: note x, note y, note z
executive summary (I simply call it a header) at the top of each result
line numbers (these can be toggled on/off within the REPL)
coming up...
file metrics
load & parse multiple files
drag & drop (windows only?)
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
I quench my thirst for plain text interfaces with Emacs nowadays, but this looks lovely and brings back DOS memories I haven't even had")
Author at Zettelkasten.de • https://christiantietze.de/
Looks very nice. Is this .txt only? No .md?
Zettel GitHub. Zettel Wiki Erdős #2. Problems worthy of attack prove their worth by hitting back. -- Piet Hein. PROBLEMS. Grooks, 1966. CC BY-SA 4.0.
Many thanks & good ol' emacs, probably the original digital assistant. Went through my LISP phase at least a decade ago. Recalls a quote I once read...
I'm always delighted by the light touch and stillness of early programming languages. Not much text; a lot gets done. Old programs read like quiet conversations between a well-spoken research worker and a well-studied mechanical colleague, not as a debate with a compiler. - Jocelyn Ireson-Paine
You know, I visited your personal website awhile back. Very interesting reading.
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Hi ZD, nice to speak with you again.
No markdown support (but doesn't choke on it either). Best to think of a tinybase data file as a notebook or container of sorts that wraps your data. Here's an example...
Screen shot below shows current iteration...
I'm using bit fields to control the REPL. For instance, to toggle profile settings (included manual explains all), simply flip a bit on/1 or off/0:
invoking .p110 translates as:
File metrics are complete now as well (even a nifty md5sum to verify shared files).
Hope to be posting a detailed explanation of Tinybase soon. 🙂
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
File metrics complete...
(1st screen shot shows metrics, 2nd screen shot for fun). md5sum is handy when you need to confirm with another that a shared file is byte-for-byte identical.
Coming up...
. Wildcard expansion when loading multiple files (unix like OSs only): tinybase *.txt
. Drag-n-drop, File associations, 'Send To' functionally (windows only)
. Paginated output with inbuilt default or set it yourself (windows: set PAGER=less.exe) (unix: export PAGER=less)
And introducing scripting support...
Release date coming soon.")
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Re: Wildcard expansion...
Done.
Re: Drag-n-drop...
Yup, all of it, complete as well. Here, I've plainly & simply described in the manual how to do these tasks for the end user (right click file & select 'open with', etc.) as it takes less verbiage to describe it than coding it!
And finally, the hexdump routine is included. I'd at first thought I'd wait till the next version, but since I finished it a while back, why not?
The hexdump function will likely be seldom used, but there are times when its quite handy, for instance...
Imagine you have some embedded control codes in your data such as a formfeed (control code ^L). A formfeed as we all know, instructs the printer to stop printing, eject the current page, & recommence printing on the next page. But some terminals, even lots of editors (ahem ~ Windows apps I'm looking at you) substitute control codes with a generic box character, which does nothing to describe the character's actual value. But we're going to solve that problem with Tinybase's inbuilt hexdump feature.
Three steps required...
1st consult the included manual for the hex-table as shown below...
2nd find the formfeed's hexadecimal value where the row & column intersect for
^L, transcribe its hex value from the left most column & top most row -0C.3rd confirm the existence of
0Cin the middle pane within the hexdump (highlighted in blue in the image above)./* 7 bit ascii/hex conversion table printable characters: 20 to 2F through 70 to 7E 0 1 2 3 4 5 6 7 8 9 A B C D E F 0 ^@ ^A ^B ^C ^D ^E ^F ^G ^H ^I ^J ^K ^L ^M ^N ^O 1 ^P ^Q ^R ^S ^T ^U ^V ^W ^X ^Y ^Z ^[ ^\ ^] ^^ ^_ 2 SP ! " # $ % & ' ( ) * + , - . / 3 0 1 2 3 4 5 6 7 8 9 : ; < = > ? 4 @ A B C D E F G H I J K L M N O 5 P Q R S T U V W X Y Z [ \ ] ^ _ 6 ` a b c d e f g h i j k l m n o 7 p q r s t u v w x y z { | } ~ DEL ^@ = NUL ^L = FF ^H = BS SP = SPACE ^Z = EOF ^[ = ESC ^G = BEL ^M = CR ^I = TAB ^J = LF Example: n = 6E */Darn, I've been hard at this a good number of days now, off to take break & then, knock on wood, finish up the manual & this project is up & running.
Wanted to offer up an earnest thanks for everyone's patience with the me as I'm acutely aware I just sort of tumbled into the forum of the blue, & even barged into a thread or two (sorry about that - still learning the netiquette in this domain). At any rate, about to be around the corner.")
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
tag index updates...
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Okay, I'm freezing the addition of any more 'features'. About 40% of the manual left (well honestly, I'd most of that written already). You know, seems to me in some respects documentation is the hardest part, nevertheless, I press onwards. Coffee...
Latest screenshots:
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Some mirth")
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Ah yes, I've grown to appreciate the form feed character thanks to the Emacs community, too, and configured the editor to display a horizontal rule
To me, this shows how gracefully Markdown solves this stuff with "ASCII art"-drawing of an actual line with e.g. dashes
That's arguable less problematic than the form feed character and other control codes.
Author at Zettelkasten.de • https://christiantietze.de/
Windows editors are the main culprit IMO. Rather than showing the control char, they simply supply a generic (often incorrect character).
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
This post describes some unique things you can do with tinybase.
The 1st example shows you how to execute content (build your own code library!) with a tag query. And the 2nd example illustrates dynamic content generation.
Ready? Lets do this..
Given a tinybase file named code-library.txt, comprising these tagged blocks...
In a unix-like OS we would invoke this expression to list all .txt files..
Under Win we would invoke this expression to list all .txt files..
The 2nd example shows you how to generate a html file. Assuming a tinybase file containing these tagged blocks:
Now then we'll invoke tinybase as shown next to create an html file...
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Really wish I could edit out my typos, but that ability seems to not be granted to me...
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Here's the results of my markdown testing here.
formfeed: only emits a new line
bel: nothing (but displays a black square with a white X within the forum editor)
tab: works or is it simply passed along? I cant tell.
eof: nothing
But in markdown's defense: neither are these printable characters either so who knows. Me? I don't think markdown should have to worry about these items since html doesn't.
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Slowly (still) rewriting the manual & also considering the addition of IPC. Example below shows the output of an unrelated command (just a random blurb) piped into the titlebar of Tinybase, perhaps for status messages? Must think about more... One of theses days, soon, this project will be complete. My take on what I'll dub the 'minimum viable product'.
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Fuzzy matching (or I can't remember the confounded card's name) using the Levenshtein distance formula:
so... fuzzy/approximate matching (poor mans regex!) looks doable on this end.
Now about the Haversine formula...
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
After a bit of wrangling, fuzzy search is going to make the cut...
And a screen grab the of environment panel...
Really happy with the way this is coming together. As my grandfather often said: 'That dog will hunt!'
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Out of curiosity, have you benchmarked your algorithm with a large data set? I dabbled with this some years back but it was unusable for my actual notes.
There's always 10k Markdown files if you want to check it out")
https://github.com/Zettelkasten-Method/10000-markdown-files
Author at Zettelkasten.de • https://christiantietze.de/
Yes, against hurdreds of thousands of tagged blocks megabytes in size. Checkout the metrics in 1st screen shot below where each file is doubled in size per iteration.
The 'trick' for speed with Levenshtein (or at least it works for me) is to only compare a user's query against the taglist not the entire body of the file. 2nd screen shot below depicts my thinking, just the tagline (highlighted in blue).
Hey nice! Thank for the test data Christian.")
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Gosh, I'm getting so darn close... & yet wouldn't be wise to rush things.
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Update, Tinybase site is here: https://xyz-software.github.io/index.html
Earnest thanks to everyone.
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Metrics update...
Starting to get exited on my end.")
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Kicking around a subset of regular expressions...
My head hurts...
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
Okay, more progress on the documentation. Hoping for a completion of the 1st draft by late next week.
Next screen shot shows what a user sees when launching tinybase...
And here's a screen shot of the profile panel...
Tinybase now features 3 modes of parsing tags:
Optional shell access & calculator (precision to 8 decimals points) ready too.
Here's a scripting example with tinybase invoked as:
Here's the contents of input.txt:
And finally here's the contents of output.txt
Off to enjoy the weekend, grandkids are in town for a day or two")
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
In 218 BC during the 2nd Punic wars, Hannibal, when questioned by his lieutenants on the rationality of crossing the Alps in the dead of winter with a herd of elephants, silenced naysayers with this reply: 'We will either find a way, or make a way'.
Just think of it, a 'packed' variable... A single digit can yield 10 differing 'settings' (0-9). That's a whole lot of value for very nearly no memory consumption. Example, profile = 75032211
/* bitmask... field description range default 0....... block color 0-8 0 .0...... header color 0-8 0 ..0..... numbers color 0-8 0 ...0.... calc precision 0-8 0 ....0... scan engine 0-2 0 .....0.. index engine 0-2 0 ......0. line numbers 0-1 0 .......0 shell 0-1 0 fields 1-3: colors default 0 black 1 red 2 green 3 yellow 4 blue 5 magenta 6 cyan 7 white 8 field 4: calc precision 0 0 1 0.0 2 0.00 3 0.000 4 0.0000 5 0.00000 6 0.000000 7 0.0000000 8 0.00000000 field 5: scan engine exact 0 phonetic 1 regex 2 field 6: index engine unsorted 0 sorted A-Z 1 sorted by occurrence 2 field 7: line numbers on 1 off 0 field 8: shell on 1 off 0 */Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
What constitutes a word?
'a' is a word, 'i' as well...
And consider non-alphabetic or even mixed groupings: '876-fubar@example.com'
Me thinks that's a valid word too. So for myself, one or more printable characters surrounded by whitespace (space, tab, newline, etc.) is a word. Nice to have an easy solution when you're banging out code.")
Also rediscovered a great quote I'd forgotten I had, good stuff...
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)
@Mike_Sanders Haha! I like that quote - fits with many similar quotes I have seen and my own (engineering) experience. Thanks for sharing.
The bolt example reminds me of a sociological study that stuck with me: "Crime and Punishment in the Factory: The Function of Deviancy in Maintaining the Social System"
https://onwork.edu.au/bibitem/1963-Bensman,Joseph-Gerver,Israel-Crime+and+Punishment+in+the+Factory+The+Function+of+Deviancy+in+Maintaining+the+Social+System/
I bet you find copies of that to read. The crux is that even though drilling new threading into bolt holes is officially forbidden and punished, there's a rather complex informal agreement on when and how to re-thread holes, if needed.
Author at Zettelkasten.de • https://christiantietze.de/
Excuse my delayed reply Geo, I've been out of town...
Chuckle, & glad you enjoyed it. Always feel welcome to post some of your own if you wish. Here's another nice one...
The chief cause of problems is solutions. - Eric Sevarei
Tinybase: plain text database for BSD, Linux, Windows (& hopefully Mac soon)