@Marcus, you are 99% of the way there. All you need to do is set The Archive's editor font to a fixed font style.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time. My Internet Home — My Now Page
Hi @Will , sometimes it can be that simple. I just changed the font to Lato today. My mistake.
Unfortunately, it's still not 100% accurate. I have now tested it with CourierNewPST and UbuntuMonto. Sometimes a dot is missing or, as in the following example, the last entry has the necessary dot more.
No great effort to correct this manually. Whereby the ideal case would be if all lines are really the same length and if there are also two spaces after the UID in [[]] and thus breaks in exported PDFs are displayed correctly.
Are there any trailing spaces between the title and uid or after the uid in the file names?
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time. My Internet Home — My Now Page
Hi @Will , I wish it were that simple. Unfortunately, it doesn't just affect the Zettel shown so far, but many different ones. I have checked the spaces (before, after, in between, too many, too few).
@Marcus, I discovered the problem, and I will work on a fix. I'm in the shop and need access to my programming tools. This may take a bit of time to fix.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time. My Internet Home — My Now Page
Don't be too liberal with the thanks just yet. I've spent some time on this and am giving up. I can't get Keyboard Maestro to correctly process the character length as opposed to the bit length of the line. I've tried various UTP-8 scenarios, awk, and JavaScript, but none work. JavaScript gets me the closest, but I can't figure out how to get a Keyboard Maestro variable into the script. Time for bed.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time. My Internet Home — My Now Page
And @Will , I would like to thank you anyway, we have finally learned something and other German users can benefit from it.
Also, it might be a good idea not to use umlauts in the file names.
I just changed my titles accordingly and am happy with your macro solution.
Alright. So any non-ASCII character will be counted wrongly (by bytes, not by perceived character width), which means all umlauts have a width of 2 or 3 (depending on how you assemble these).
Solution
The good news is that character counting instead of byte counting is possible.
The bad news is that this requires a custom .sh script to perform the formatting, or a shell function.
File
Stored as e.g. ~/bin/columnized.sh, then calling that from a macro:
I don't understand something linguistically. What is the difference between these two characters, and why would they behave programmatically differently? The first character is counted as 1, the second is counted as 2. This is using the bash script @ctietze provided.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time. My Internet Home — My Now Page
this comes from French and if I understand it correctly, they are there to make words sound different. This is useful, for example, with two very similar sounding words.
accent aigu (á)
accent grave (à)
There are also accent aigu (é) and accent grave (à, è, ù) and accent circonflexe (â, ê, î, ô, û).
Example: ou = or / où = where.
Unfortunately, I don't know why they are counted differently.
@Will It's that machines are bad at counting what we perceive as characters, not what characters are linguistically.
This chart from the Unicode Report TR15 shows how to compose and decompose a ligature, mathematical power, and accents over a variant of the letter "s" you don't see often:
Imagine the accented character behaves more akin to the "s" in the bottommost row. There is a composed normal form with an "s" and two dots that uses one Unicode codepoint, U+1E69. But you can also use forms with 3 code points. A code point here is two bytes, say, then you have the same 'idea' of the letters intent transmitted in either 2 or 6 bytes. Most computer-based programs, especially on the Unix/POSIX-compatible shell, ignored everything out of the US-ASCII plane until the 1990's (I'm simplifying). You could not display accented characters reliably at all. Now we can, there's an encoding for this, but the software often still counts bytes when they count characters (which is wrong).
Can recommend talks by Dylan Beattie. His tech talks are for a very broad audience, and fun, if you want to dive deeper and know about the magical fact that we can write messages on the internet at all:
Try emoji. Especially the family emojis, which are just a concatenation of the family member emojis, displayed as 1 'character' for us, or technically: "Graphemes". They take up a lot of bytes.
Edit: the family emoji are discouraged nowadays I learned, because combining with skin tones didn't scale or so? https://www.reddit.com/r/ios/comments/1b9ar70/why_did_apple_get_rid_of_the_family_emojis/
Anyway, shell programs usually don't count them well:
The 😂 FACE WITH TEARS OF JOY Emoji is encoded as F0 9F 98 82 in UTF-8. That's these byte sequences:
11110000 announces 4-octet character
10011111 continuation character + 011111
10011000 continuation character + 011000
10000010 continuation character + 000010
Comments
@Marcus, you are 99% of the way there. All you need to do is set The Archive's editor font to a fixed font style.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Hi @Will , sometimes it can be that simple. I just changed the font to Lato today. My mistake.
Unfortunately, it's still not 100% accurate. I have now tested it with CourierNewPST and UbuntuMonto. Sometimes a dot is missing or, as in the following example, the last entry has the necessary dot more.
No great effort to correct this manually. Whereby the ideal case would be if all lines are really the same length and if there are also two spaces after the UID in [[]] and thus breaks in exported PDFs are displayed correctly.
In any case, thank you very much for your work!
@Marcus You need a monospace font.
I am a Zettler
Hi @Sascha , monospace makes no difference. Here is a screenshot with UbuntuMono.
The same applies to PTMono or Andale Mono.
And here also with the font IBMPlexMonto from Will:
I added two more notes because I wanted to test whether it might be due to the “Kommunikationstheorie Luhmann” note.
Are there any trailing spaces between the title and uid or after the uid in the file names?
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Hi @Will , I wish it were that simple. Unfortunately, it doesn't just affect the Zettel shown so far, but many different ones. I have checked the spaces (before, after, in between, too many, too few).
@Marcus, I discovered the problem, and I will work on a fix. I'm in the shop and need access to my programming tools. This may take a bit of time to fix.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Hi @Will , that's what I call eagle eyes! 😁
I hadn't noticed that aspect at all, and that's after staring at so many screenshots.
Thank you very much for your commitment.
Don't be too liberal with the thanks just yet. I've spent some time on this and am giving up. I can't get Keyboard Maestro to correctly process the character length as opposed to the bit length of the line. I've tried various UTP-8 scenarios, awk, and JavaScript, but none work. JavaScript gets me the closest, but I can't figure out how to get a Keyboard Maestro variable into the script. Time for bed.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
It should look better-aligned if you switch to a monospace font
Author at Zettelkasten.de • https://christiantietze.de/
Hi @ctietze , I already use monospace fonts.
And @Will , I would like to thank you anyway, we have finally learned something and other German users can benefit from it.
Also, it might be a good idea not to use umlauts in the file names.
I just changed my titles accordingly and am happy with your macro solution.
Sorry I was looking at page 1 and didn't notice that there were more posts")
Author at Zettelkasten.de • https://christiantietze.de/
Alright. So any non-ASCII character will be counted wrongly (by bytes, not by perceived character width), which means all umlauts have a width of 2 or 3 (depending on how you assemble these).
Solution
The good news is that character counting instead of byte counting is possible.
The bad news is that this requires a custom
.shscript to perform the formatting, or a shell function.File
Stored as e.g.
~/bin/columnized.sh, then calling that from a macro:#!/usr/bin/env bash # Column width cw=40 # Receive 2 parameters: $1 (col1) and $2 (col2) col1="$1" col2="$2" # Calculate proper spacing for multibyte characters printf -v padded_col1 '%s%*s' "$col1" $((cw - ${#col1})) '' # Print aligned columns printf "%s%s\n" "$padded_col1" "$col2"Function
A function would work as well, but only be useful in interactive environments (e.g. not your scripts most likely):
format_columns() { local cw=40 local col1="$1" local col2="$2" printf -v padded_col1 '%s%*s' "$col1" $((cw - ${#col1})) '' printf "%s%s\n" "$padded_col1" "$col2" }Test
@Will maybe this helps get your macro rocking?
Author at Zettelkasten.de • https://christiantietze.de/
I don't understand something linguistically. What is the difference between these two characters, and why would they behave programmatically differently? The first character is counted as 1, the second is counted as 2. This is using the bash script @ctietze provided.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Hi @Will,
this comes from French and if I understand it correctly, they are there to make words sound different. This is useful, for example, with two very similar sounding words.
accent aigu (á)
accent grave (à)
There are also accent aigu (é) and accent grave (à, è, ù) and accent circonflexe (â, ê, î, ô, û).
Example: ou = or / où = where.
Unfortunately, I don't know why they are counted differently.
@Will It's that machines are bad at counting what we perceive as characters, not what characters are linguistically.
This chart from the Unicode Report TR15 shows how to compose and decompose a ligature, mathematical power, and accents over a variant of the letter "s" you don't see often:
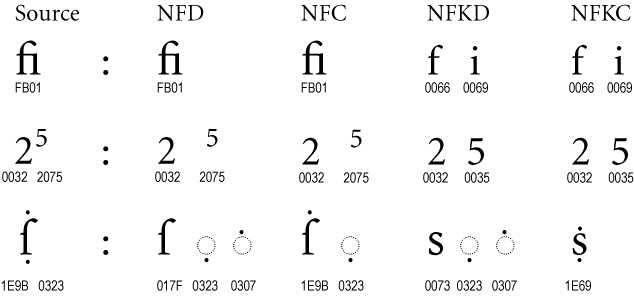
Imagine the accented character behaves more akin to the "s" in the bottommost row. There is a composed normal form with an "s" and two dots that uses one Unicode codepoint, U+1E69. But you can also use forms with 3 code points. A code point here is two bytes, say, then you have the same 'idea' of the letters intent transmitted in either 2 or 6 bytes. Most computer-based programs, especially on the Unix/POSIX-compatible shell, ignored everything out of the US-ASCII plane until the 1990's (I'm simplifying). You could not display accented characters reliably at all. Now we can, there's an encoding for this, but the software often still counts bytes when they count characters (which is wrong).
Can recommend talks by Dylan Beattie. His tech talks are for a very broad audience, and fun, if you want to dive deeper and know about the magical fact that we can write messages on the internet at all:
14min intro
50min talk
Also:
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
TLDR: It's a mess.")
Try emoji. Especially the family emojis, which are just a concatenation of the family member emojis, displayed as 1 'character' for us, or technically: "Graphemes". They take up a lot of bytes.
Edit: the family emoji are discouraged nowadays I learned, because combining with skin tones didn't scale or so? https://www.reddit.com/r/ios/comments/1b9ar70/why_did_apple_get_rid_of_the_family_emojis/
Anyway, shell programs usually don't count them well:
The 😂
FACE WITH TEARS OF JOYEmoji is encoded asF0 9F 98 82in UTF-8. That's these byte sequences:Asking for a character and byte count:
$ echo "😂" | wc -m 2 $ echo "😂" | wc -L 4So to do this in a shell script, we need to pipe to maybe Perl?
https://stackoverflow.com/a/78902324/1460929
Good news is that we can also do this in JavaScript:
then a plugin for The Archive can do this")
Author at Zettelkasten.de • https://christiantietze.de/