Cardcraft And Atomicity

In a comment, @harr asked
@tomp said:
I'm mostly interesting in moving away from paying too much attention to whether a note is "sufficiently atomic" and thinking instead of what the note is supposed to be for, and crafting it so that it promotes that purpose in a helpful way.
(…)
I think the focus should be on cardcraft and not atomicity. Realizing that a card is usually best when it is about one subject is part of cardcraft; but it's only one part.Interesting topic. Would you mind starting a new thread, so that we can chime in?
Happy to oblige. By cardcraft, I mean all kinds of techniques to make a z-card effective. So what makes for an effective z-card? To some extent it depends on what one wants the card to do. I think that a card should generally be about one subject, but whether that is the same as "atomic" is another question. Let's not get into that here - for now, let's just say that the card should usually be about a single subject without being too particular about what that means.
Why does a card exist? I have cards that remind me of the right syntax for a computer command. Useful but not very exciting. The main thing I want from them is that I can find them when I need them. That, at least in my system, is mostly about the title. I also want to be able to find the actual command easily when I scan the card.
The purpose of a card might be to comment on a quotation, to collect a number of sources about a subject, to capture one's speculations about "consciousness", to be part of a chapter for a book, to keep the correct citation form for some published work, to act as a structure card, just to name a few. I want my cards to help me pick up the card's purpose.
For this discussion, I created a mind map to help me work out the things I wanted to write about. I put a link for it into a card. Actually, I put a link to both the mind map and its .png image file. I can open either one with a click. That way I don't need to go fussing around trying to find the right file. There is no computer machinery to get in my way.
As usually happens, working on the mind map got my mind associating and I kept thinking of things to include. As I wrote, some of the points made their way back to the mind map. By now there is too much material for this post and I will have to cover some of it once over lightly. Here is an image of that mind map.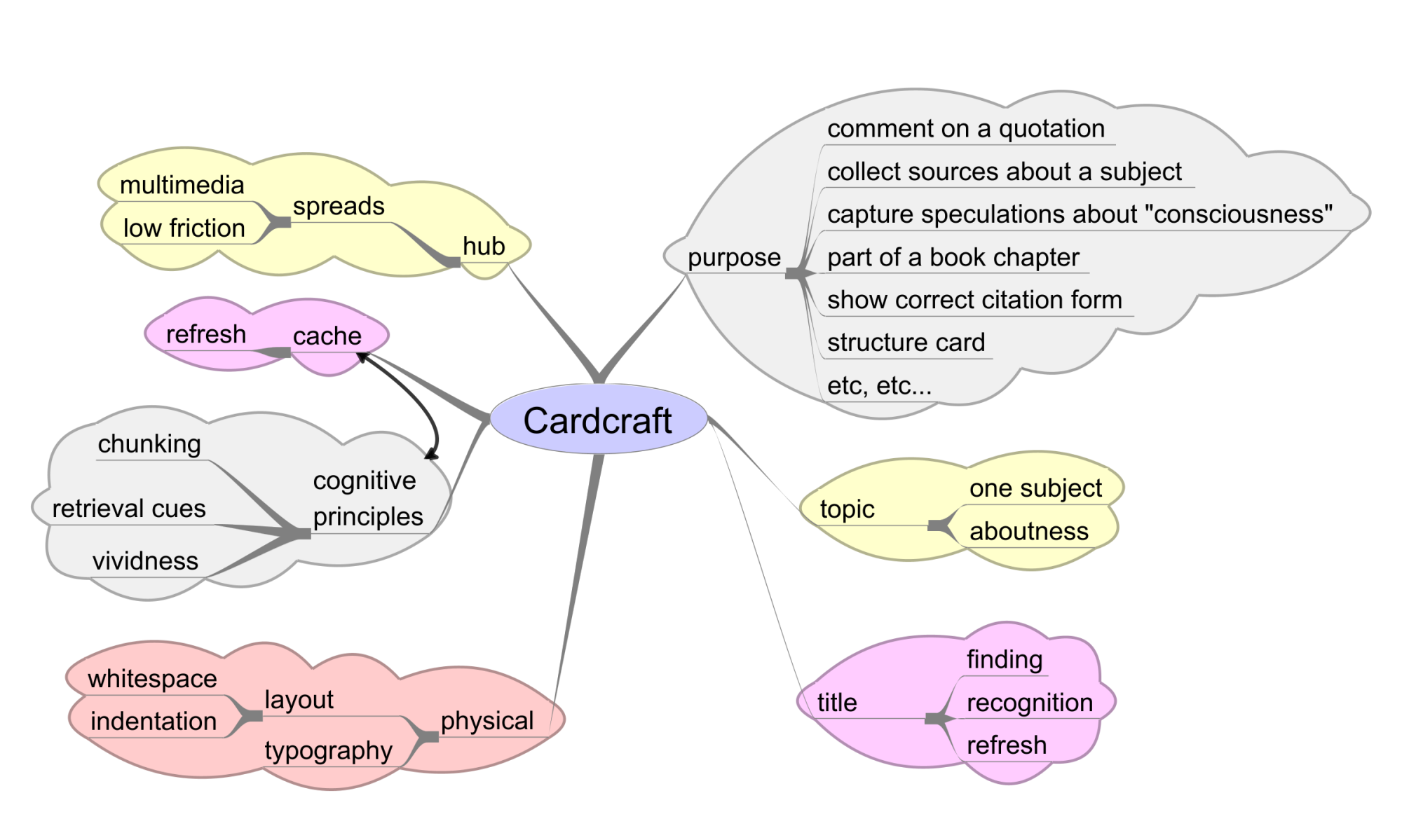
Of all the branches in the mind map, all the ways in which a card can be tuned up for its purpose, note how there is only one related to the subject (the "aboutness") of the card; or two if you include the title. The aboutness is important, no doubt about that, but it's only one of many things involved in making a card that can sing to you.
Let me just talk about a few of the elements. Refresh means to recreate the mental state or "scene" which was active when that card was created. That scene will naturally depend on the card's purpose. All the elements aren't needed for every purpose.
"Cache" means to save for later use, a time when one will come back to the work. The idea is that one's mental scene will get refreshed by the card. Any z-card can only be a flattened and compressed version of one's thoughts, so it is worth while to work on adding some depth with the aim of having the card un-compress and un-flatten in the mind when one returns to it.
By typography I mean mostly boldface and italics, though if the ZK system supports more, great.
The branch labeled title refers to working up a title that will help the user to find the card, and to serve as a reminder in itself as to what the card is about.
Spreads means spreads of multiple cards, images, etc., across a screen as if they were actual physical cards and photos. A card can be a multimedia hub. It helps to have a second monitor but even with just a single monitor one can put up a small spread. Right now I have the image of the mind map up on my second monitor. I have been looking back and forth at it as I write.
Every card does not need all these elements. But many will benefit from some of them. Even if you only pay attention to the title, physical, and cognitive principles branches you will have nine ways to enrich your cards.
To Illustrate, here is a side-by-side view of a card with the basic content of the mind map as an indented list (I can copy-paste this directly from the mind map editor). It is contrasted with a crafted version, shown in a rendered view. Which one speaks more vividly to you?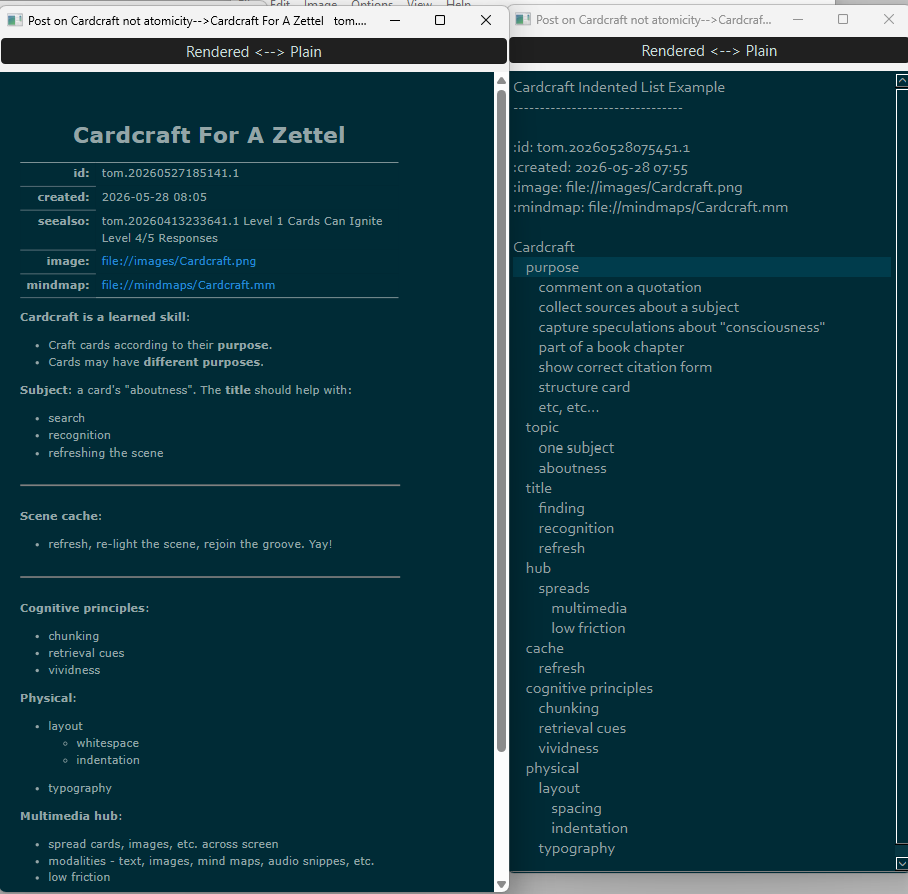
Howdy, Stranger!
Categories
- 3K All Categories
- 152 Research & Reading
- 692 The Zettelkasten Method
- 7 Knowledge Work
- 100 Writing
- 464 Software & Gadgets
- 154 Workflows
- 730 The Archive
- 15 Plug-In Showcase
- 88 Resolved Issues
- 225 Projects Logs and Journals
- 83 Project: Zettelkasten.de
- 53 Critique my Zettel
- 171 Random
- 373 Introduce Yourselves!
Comments
@tomp, I have a couple of suggestions for improvement of your framework here.
First, if this framework is for your personal use, then it may be sufficient, but if it's for general use, then the variety of systems of knowledge organization could be expanded beyond what you call topics. See, for example, the various figures in the third section of Maria Teresa Biagetti's article on "Ontologies as knowledge organization systems" (which are not exhaustive). This point is particularly obvious to me because my own note system is not organized by topic. In a topic-based knowledge system, a topic could be atomic, but other systems of knowledge organization could have other types of atoms or knowledge building blocks.
Second, I think physical is not the best label for that category; what you are referring to (typography, layout, etc.) is more precisely user interface design or graphic design. What you call spreads would also be part of this category. I'm reminded of the user interface category in the analytical framework in Davies et al. (2005) (full citation in the footnote here and previously mentioned here):
1.1. Structural framework
1.2. Knowledge elements
1.3. Schema, or formal semantics
Cardcraft (Zettelhandwerk?) is a nice term, but if we take into consideration all of the elements from Davies et al., we're dealing with personal knowledge system craft (Zettelkastenhandwerk?) instead of just cardcraft.
Andy, thanks for the thoughts. My orientation is naturally towards my own use and interests but I'm also trying to bring in what I have taken away from Luhmann's writings, and what I've been reading on line. I have some background in topic maps, RDF, and similar systems, and they are usually organized around subject-predicate-object statements in one disguise or another. In fact, they constitute one part of first-order logic.
Could you say more about your own system and its organization? I'm very interested.
I agree with you there. I'm not sure yet what I want to call the idea and I just punted for the purposes of my post.
That basically describes a software architecture called "Model-View-Controller", or MVC. I'm not quite sure how it's used in that framework but a formal schema is not necessary if we are talking about an actual piece of software. I argue, though, that there is always at least an implicit schema, possibly not complete or fully consistent.
I agree modulo that I was limiting my post to just the card portion. I think of the organization of the whole as a complementary piece.
If we think in term of library science, I think the kind of organization that most Zettelkasten users build up is better described as a subject language. But unlike the subject languages envisioned by library science practitioners, they are mostly informal, inconsistent, and will drift over time. They are certainly neither an ontology, a hierarchy, nor a faceted language.And these characteristics are a feature, not a bug, for a rich Zettelkasten system, IMO.
These informal and inconsistent characteristics would be unwelcome for a system that has to be used by large numbers of users, and has to stably and reliably fulfill the objective of navigation and collocation. But that's not what we are working with, by and large. That's certainly not what Luhmann created for himself.
I think that Biagetti's use of the term "Knowledge Organization System", much like the term "Personal Knowledge Management System", is too rigid and limiting for what I hope to get out of my Zettelkasten. I want a superset. The classic measures of recall and precision are not enough. What remains important from library science are the two objectives of navigation and collocation.
What features would that "superset" have?
I'd also call it visual when I wanted to put the emphasis on perception. This kind of information is processed differently in the brain than structural aspects.
Instead of cognitive principles I might talk about memory a for chunking and retrieval cues.
I also enjoy card craft as a term. I love alliterations. :-)
The term is compatible with the English term index card.
Thinking of personal knowledge management as a craft makes sense to me. A craft can be learned and taught and practiced.
I also like that card craft centers the card as a container instead of the abstract concept idea or the ambiguous word note.
@Andy said:
You have picked up on the very connotations I have in mind. I have a card on the learnable aspect, with the title "ZK Cardcraft is Teachable".
Recall and Precision are measures that focus on finding exactly what is wanted, or at least documents as close as possible to it. That is an important function of a PKMS. I, and I am sure most Zettelkasten practitioners, hope to be surprised, to make unexpected connections, to notice new patterns, to have new trains of thought kicked off. We're not going to get that just by "managing" what we already know.
There's your superset.
Luhmann knew this distinction well:
Luhmann himself was very constrained by the paper-based nature of his system. So he de-emphasized the PKMS parts and emphasized the superset parts. This was the complete opposite of a traditional library science style card catalog. The strengths of his system would involve the practitioner, chance, and surprise:
I claim that with a good computerized design, based on good principles, used with good craftsmanship, we can have both because we can have our Zettelkasten be a superset of a PKMS. Much of what Sasha writes, for example, is in essence about the craftsmanship aspect.
What principles do you have in mind?
@tomp said:
For a long time my ideal in my note system has been to organize notes as structured argumentation using an informal IBIS-like schema (though not everything in my notes is so well organized). In Joel Chan's recent work (e.g., in the paper "Steps towards an infrastructure for scholarly synthesis" by Chan et al. 2024), this type of data model is called a discourse-oriented data model and the resulting knowledge base is called a discourse graph, but sometimes Chan seems to use this term to refer to his own particular model of discourse graph. I think that's a great term, but I wish they would more clearly use the term to refer to a type of data model instead of to their particular model. When I googled the term now, I discovered that Chan et al. have a relatively new website that I hadn't seen before, discoursegraphs.com, and they have formal schemas for their particular discourse-graph model on GitHub.
Yes, I think that's right. My own schema is explicit but not very formalized.
Nice! Last time I was searching for a solid source for "QCE" (questions claims evidence), I didn't see that website either. Very helpful, thanks.
Same here. It makes it difficult to compare Chan's model with earlier models, like Novak's concept maps or Horn's argumentation maps.
@harr: As you may know, Robert E. Horn is just one of many researchers of argument mapping or argumentation maps; for example, he was one among various authors of chapters in the edited collection Visualizing Argumentation: Software Tools for Collaborative and Educational Sense-making (Springer, 2003).
I take the terms "discourse-oriented" and "argumentation-oriented" to be roughly equivalent, when the terms refer to a general type of data model or schema. For example, the book The Craft of Research by Booth et al. describes research "argumentation" in a way that is much the same as how Chan et al. describe research "discourse". But some people may prefer a stricter conception of argumentation, and for them the term discourse can be taken as a closely related but more general domain.
Where particular discourse/argumentation schemas have been formally specified in an ontology language and diagram, they can be relatively easy to compare. I think we could say that such a specification identifies what the knowledge "atoms" are in that schema, which should help the user think about "what the note [or node] is supposed to be for" (in @tomp's words).
But one can do basic Zettelkasten-Method work without knowing any of this argumentation-theory stuff; this is all at the deeper level of thinking tools in Sascha's iceberg model.
I looked at the discourse graphs web site. I haven't gone deeply into it but I seriously disagree with what I see in the basic data model. It is missing many of the most important factors. Evidence does not directly support claims. A claim is a multiway relationship between what is claimed, the evidence, relevant theory, arguments that explain how the evidence and theory play together, and analysis that stresses or tests the support for the claim. Deborah Mayo, a philosopher of statistical evaluation and analysis, emphasizes the point that claims need to be "severely tested", and I am using the "analysis" entity to represent that stressing activity.
This data model can be expressed in Entity-Relationship or Topic Maps terms, just to name two approaches, but in no case should those unrepresented components be left out. It may be that in some specific cases some of them can be elided or folded into others but IMO they should be explicitly exhibited in the basic model.
I had more superficial similarities in mind, ie basic visual mapping that captures the connections between elements of discourse with labeled edges.
Yeah. I'm aware of Sascha's six knowledge building blocks. Has anyone made the effort to compare them with more elaborate theories?
Personally I find Chan's QCE surprisingly useful when I'm unsure about the granularity of some zettels.
I think it depends on the application. For the purpose of personal note-making I find formal methods too complex.
Why bother with the completeness of a model, that I would never apply?
When I want to apply a formal method to a real life problem, I pick an existing specification and use it as specified.
Or I take them as an inspiration for a non-formal application, as I do it with QCE. But in that case I don't bother with details or imperfections.
By definition: The Zettelkasten Method is a set of workflows and tools mainly for architecture. It is agnostic to the theory of knowledge that you are using as the foundational layer.
For an extreme example: You could make the foundational layer following the rules of gossip. Gossip can be viewed as a web of ideas, too. The Zettelkasten Method is even compatible with that.")
This is why you don't have to decide for one of these concepts:
I think that discourse-oriented should be separated from argumentation-oriented for the reason that you gave: Discourse is a superset of argumentation.
But some areas of your Zettelkasten can be discursive while others remain argumentative.
I am a Zettler
I'm on board with avoiding complexities of formal models. It's a principle I followed in setting up my own system. However that doesn't mean they aren't there, if only by implication.
@tomp said:
I agree that their model is missing elements that are important for scientific work. At the same time, I agree with @harr that such a model needs to be simple enough to be usable. Because the balance between model comprehensiveness and usability will be different for different users, I think Chan et al. should put more emphasis on how to craft conceptual models for discourse graphs instead of emphasizing their own model so much. Chan cited a great paper, Hars (2001),1 that shows how Hars synthesized his own conceptual model (ontology) of scientific knowledge from existing models, and Chan et al. should emphasize that more. At a minimum claims need to be attacked (one way of representing "testing" them), which is emphasized in IBIS but apparently not in Chan's QCE model.
@Sascha said:
On second thought, I agree with that. I was thinking that discourse in the context of research is generally argumentative, but even that much is probably not true given the use of different discourse modes even in academic research.
Alexander Hars (2001). "Designing scientific knowledge infrastructures: the contribution of epistemology". Information Systems Frontiers, 3(1), 63–73. ↩︎
I agree too. My approach has been to use convention and implication to replace the formal elements as much as possible. For example, in the Topic Maps model a topic, which represents some subject of discourse, has a "subject identifier" that indicates the subject. It might be a reference to a web page, an identifier in a well-known catalog, whatever. In a z-card, I know that the card itself says what it's about, so I don't have to include a subject identifier.
A Topic Maps topic also has a type (there is usually a hierarchy of topic types). But almost always in a ZK I don't actually need to know or specify the topic type. So it would be a generic type, but there is no need to say so: if the card has no type specified, then its type is the generic type - obviously.
So the formal ideas are there but mostly by implication unless there is a need to be more specific.
I prefer to look at these systems in terms of how they can help people in their thinking endeavors, in contrast to mixing in theories of knowledge and its hypothetical building blocks. So I think in terms of kinds of "thinking support" - I make no claim to understanding what "thought" is but "thinking" is an ongoing activity, whatever a "thought" is.
And yes, I have my own framework, not inspired by Sasha's diagram:
It's true that these are not always so cleanly separated but this framework helps organize my thinking. I consider traditional PKMS systems to cover Levels 1 - 3. The kinds of experiences Luhmann wrote about, the ones that got so many interested (including me) in the first place, live in Levels 4 and 5.
As best I can tell, Luhmann thought that one can either have Levels 1-2, or 4/5. He went mostly for Levels 4/5. His chains of thought were, I suppose, a manifestation of Level 3 support. With the help of computers it's clear to me that we can support all five levels with the same system.
It's also clear that the system, and the levels, will not automatically produce any results. They can only support the practitioner, who must be receptive and, yes, lucky. Luhmann wrote the same thing.
Even an apparently Level 1 query can spark connections and new ideas, if the user is in the right mindset at the right time. Let's have our systems promote those kind of outcomes as much as possible.
I'm curious why you created your own framework instead of using Sascha's (or another existing framework like IBIS).
Would you mind joining in a little experiment? As we're talking about frameworks, we could try an IBIS-inspired approach. (I have zero experience with IBIS; I hope the experts will chime in and point us in the right direction.) Here we go:
Question: Should I Sascha's framework for my zettelkasten or should I design my own?
Learn from the master.
Do my own thing.
Learn from Sascha's experience and adapt/extend the framework to match own needs.
That sounds like a setup but I'm not biting. I came to Zettelkasten with many years of experience in understanding, implementing, and working with what I now call ancestral ZK, or "Zettelkasten-light", systems. I didn't start making things up out of nothing.
Some of the apparent differences arise from different kinds of approaches and probably different modes of mentation. Sasha wrote about how to compose building blocks of thought. I write about what kind of system will promote (or hinder) the kinds of things I'm interested in (and it seems, there is some real overlap between Luhmann's interests and my own). That in turn gets me thinking about just what activities the system should support. Of course, that includes visualizing how one would or could interact with it.
My concepts are influenced by library science, cognitive science, data modeling, markup languages, systems engineering, and some knowledge of user interface considerations. So of course I will have a different perspective from Sasha, or yourself.
My current ZK system is an extension of a previous ZK-light system (which in turn is a complete re-implementation of a previous system); they both consist of a very lightweight set of scripts that overlay an existing open-source GUI outliner program. I think that using an outliner has many advantages, but at the same time I know that keywords, tags, structure cards, etc., are in some ways logically equivalent to (parts of) outlines. In fact, one can use tags, structure cards, etc., in an outliner setting if one wants to.
I don't want to tell anyone that they have to or should use one or the other, or use my exact methods. But I think I have learned some things, and I'd like to share that.
I'd like to learn why you chose particular alternatives.
Personal example: I never got the hang of the zettelkasten style, where you try to title all notes with declarative sentences. It felt awkward and artificial. I had a similar experience with the six blocks. They made it hard to think. I barely wrote zettels, because it felt like a chore.
Everything changed, when I added two elements:
Non-hierarchical local context. That's an inspiration I took from Luhmann's note sequences and Buzan's mind maps. Both encourage associative thinking, even if they appear hierarchical on the surface. Both place zettels/notes/thoughts in a local context. The structure is tree-like. Each zettel has ancestors, some have siblings or descendants. I find it much easier to write zettels with their local context in mind, instead of striving for perfectly self-contained notes.
Questions. I found it liberating to learn in the forum about systems like IBIS and QCE that embrace questions. Once I included questions as a distinct kind of zettel, it became easy to also write declarative statements. The questions provide the local context and a focus for thinking. (See the example above. It took only a few minutes to write down the arguments, because I had a question as a starting point.)
@harr, I like your previous comment!
I should correct something I said above. I said:
Later I suspected that omission I alleged in the QCE model sounded too stupid to be correct. Checking the QCE model diagrams (an older one here and a more recent one here confirmed that I wasn't correct.
It had been a while since I had examined the QCE model, and I was too quick to confirm @tomp's criticisms. I still agree that there are missing elements, but the QCE model does not necessarily overlook analysis or severe testing (i.e. refutation and refutability) as @tomp suggested.
The exclusion of the missing elements from the QCE model can be explained as being outside the scope of the model, which is aimed at being a "minimal shared schema" to facilitate interoperability between researchers' local models that have more node types and/or different labels.
By the way, I've been laughed at before in this forum for talking too much about IBIS, and I don't want to repeat that mistake again here, but I can't resist pointing out that IBIS was originally implemented on paper cards in the 1960s/70s, so it is not so far from the subject of physical cardcraft!
I don't know what you mean by the "six blocks". I don't try to title notes with declarative sentences, or any kind if sentence. I try to title them with some phrase that will be distinctive, which can be done better with some than with others.
I think we are totally on the same page here. As I know you must have noticed, I use mind maps a lot. An unadorned mind map is equivalent to an indented list, and an indented list is a very common and easy way to note down related ideas when you don't need to commit exactly to the relationships between the items. Both ways suit me and I go back and forth. Working out how to open a mind map from within a card made a big improvement for me.
I also (not always, of course) start working on a card with an indented list. I may paste the list in directly from a mind map if I had started it there.
An outliner presents items as an indented list, so it's a natural so far as I'm concerned. I think of each of them (mind map and outline) as a kind of projection of the content of the same collection. Other projections would be welcome if they are useful. I have rarely found a spring-loaded mesh layout to be very useful so I haven't tried to work one up as a ZK projection.
I haven't been using my system for this style of development, mostly because I haven't needed to yet (read that as "it didn't occur to me so I haven't tried it yet"). However, the location in the outline and the child nodes there constitute a contextual neighborhood, one that's easy to scan. In fact, that's one of the things I appreciate about using an outline. It's easy to scan a neighborhood and see what seems to be related.
Here's a screenshot that shows how I've approached a thread of thought. It's not very sophisticated yet but it's a start. This part of my ZK is for ideas I thought were interesting but are still in a preliminary form. I may move them to a more permanent place later. The node with four children at the top contain the thread of thought. The view of the selected node on the right is the rendered version. There is also an editable (unrendered) version in the "Body Editor" tab. Sorry it's hard to read but you can open it in another browser tab or window and get a larger view. The panel at the bottom left on one view of my search panel, which clusters hits on card titles under their paths. This way, even the search results show some context.
We're not the first to wrestle with these matters, that's for sure!
Sascha's six knowledge building blocks. See the 2016 list and the current list. Most recent discussion: The Iceberg Model and Atomicity. Thanks @Sascha for splitting off the thread.
Nice! I have a comparable layout in Obsidian with the plugin VirtFolder.
What app can we see in the screenshot?
The underlying software is the Leo Editor, an outliner in the MORE tradition that has been around for something like 25 years and is still actively developed. It's written in Python, is cross-platform, and is fully scriptable. Many people use it as a programming editor and it has a lot of affordances for programming - and it is a great tool for programming - but it's good for much more.
My system constitutes a custom search panel (about 1000 lines of code), half a dozen little scripts that run the ZK, and a few more utility scripts. The entire outline is in-memory. So latency is very low, and neither the cards (nodes in the outline) nor their place in the tree are tied to the organization of the file system in any way.
The entire outline with its contents can be written to a text file in that is easy to parse in case someone should need to move to another platform. That was one of the invariants that I insisted on for the ZK design.
The outline consists of nodes. Each node has a title and a "body", which is the editable text. For the ZK, a node is either a z-card or an organizer node - meaning the subject headings that structure the outline. A search has two branches: the z-card titles and the organizer node titles are searched separately and presented with different formats in separate tabs. I have used this design over several implementations covering more than 20 years in substantially the same form because I think it is very effective.
One key point of using an outline is that it should not be derived from the cards. In programming editors one often sees a tree view that is derived from the classes, methods, and functions. That is not the best plan for a ZK because the organizer nodes capture important semantic and relational knowledge that is in your head but not in any card. Since the outline grows and changes over time reflecting the practitioner's mind, it does not impose a rigid predefined structure of the kind that Luhmann cautioned about.
Structure cards could represent parts of the outline, but I normally let the outline itself do that job. Any node can be cloned and put into another location in the outline - along with its descendant nodes - and you could even build up a special section of the outline with clones of all the nodes you want to see together, to make them easy to refer to.