Definition Folgezettel

Can somebody please explain to me what a Folgezettel is?
(In the sense of Luhmann…)
After reading all the stuff over here and on other sites, Lüdecke etc pal pal… I am still somewhat unclear on the concept.
Here is the example-structure from the "classic" article on the subject:
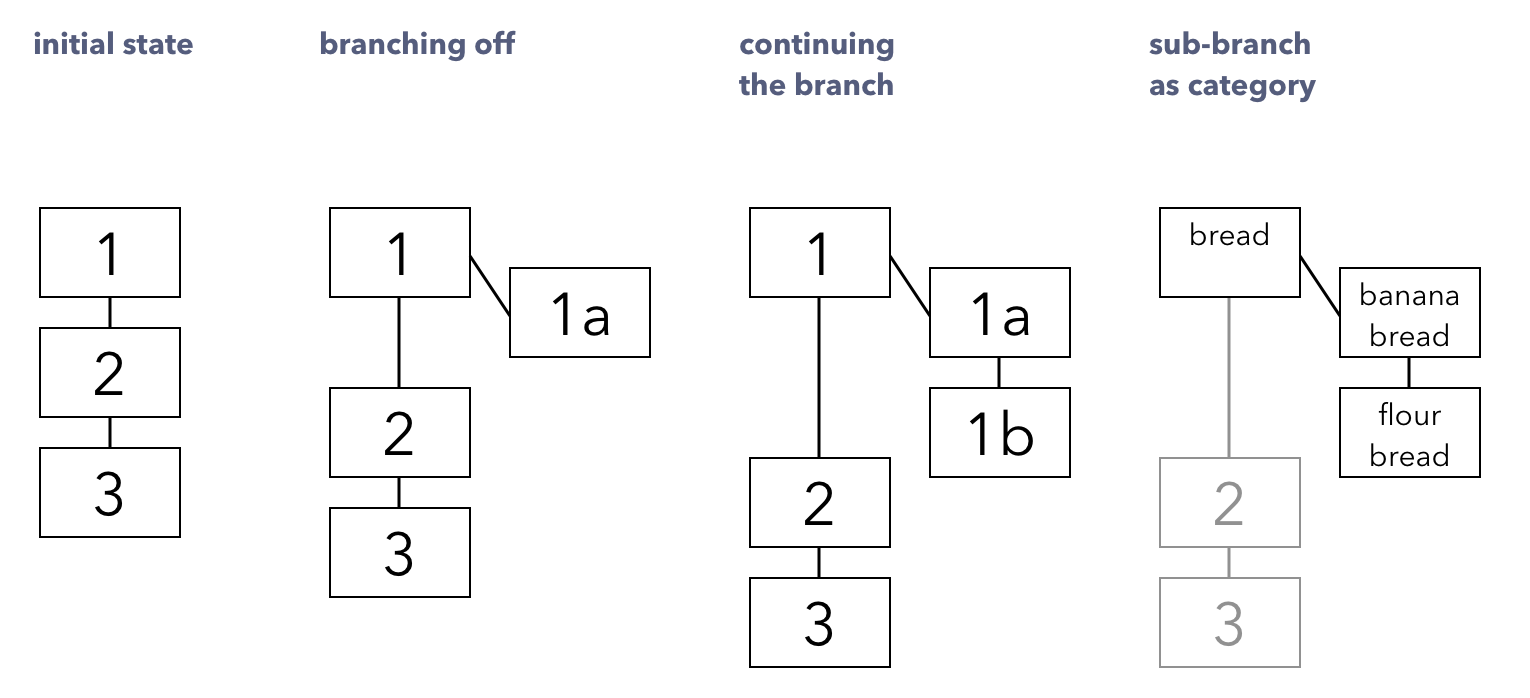
Here are my question:
- Is Zettel [1a] a Folgezettel from Zettel [1]? (y/n)
- Is Zettel [1b] a Folgezettel from Zettel [1]? (y/n)
- Is Zettel [1b] a Folgezettel from Zettel [1a]? (y/n)
and:
Why did they (or Luhmann) call it a Folgezettel then?
Howdy, Stranger!
Categories
- 3K All Categories
- 152 Research & Reading
- 692 The Zettelkasten Method
- 7 Knowledge Work
- 100 Writing
- 464 Software & Gadgets
- 154 Workflows
- 730 The Archive
- 15 Plug-In Showcase
- 88 Resolved Issues
- 225 Projects Logs and Journals
- 83 Project: Zettelkasten.de
- 53 Critique my Zettel
- 171 Random
- 373 Introduce Yourselves!
Comments
I would like, if I may, to add few further questions on the concept of folgezettels. Which of the below could be considered as critical features of this concept?
Or perhaps the I'm missing all the critical features and they are something else instead?
This discussion may help with some of the questions:
https://forum.zettelkasten.de/discussion/288/question-on-numbering
Thanks for the link @MikeBraddock, but at least in my case the problem is not how to manage a Zettelkasten using some sort of Folgezettel Zettel numbering scheme. I do that already.
My problem here is the usage of the very specific word "Folgezettel" by those who use it, which does not seem to follow a absolute coherent pattern.
I want to find out, which exact aspect of a Zettelkasten using Folgezettel is to be named just that - Folgezettel.
The word itself seems to suggest that it refers to a certain type of Zettel.
But the more I read from Lüdecke and @Sascha about it, the more confused I get. They seem to see a Folgezettel less of a thing but more as a role a given Zettel plays.
But who knows, I am confused. That's why I am asking.
The pursuit of clarity is still in progress. There are many views and opinions here and not a lot of consensus. Your quest is a noble cause which I hope others will contribute to. It is the weekend and there may be Folgezettel weariness. I am sure the conversation will pick-heat back up.
@Perikles Thank you for opening this discussion.
So, one of my hickups occured when reading You Underestimate the Power of the Dark Folgezettel – Strenge Jacke! where Daniel Lüdecke replies to @Sascha like this:
In his first bullet he equates a Folgezettel as singular to a sequence of notes. Now, this is really worse than the worst fastlish and the guy holds supposedly a PhD in the humanities but can't be arsed to write proper blogs. Oh, well.
Then, in the second bullet he uses Folgezettel as plural for the sum of all Zettel linked via Folgezettel IDs. He referes to the technique as such. Then he clarifies that by offering a "note sequences" in round brackets.
I think what happened here is that he just transliterates Folgezettel singular with "note sequence." The preceding "A" is classic sfastlish. In typical German manner he juxtaposes it to the other "A" that commences the second bullet:
"Ein…"
"Ein… …hingegen…"
I am still confused. His first bullet reads as if with Folgezettel he refers to a slip of that type, but then in the second bullet that seems to be not the case again.
It might help to not think of a Folgezettel as a type of Zettel or slip. But instead, think of a Folgezettel as a type of link or connection between Zettels. They are UID's, unique identifiers, that can be used as for direct linking as in the second bullet and ordering as in the first bullet. The difference they have over DateTime UID's is they provide a different more deliberate manually created sequencing. DateTime provides chronological sequencing and can be used for direct linking that just happens without a lot of deliberation by assigning the DateTime to the Zettel.
I am still trying to understand them. That's what I think I know about them so far.
It doesn't get better.
In the aforementioned blog, Lüdecke asserts: " A Folgezettel or a note sequence was not primary used by Luhmann because of physical limitations of small paper where to write notes on."
But on the slides for the talk he links to just one sentence prior, he makes the contradicting statement:
Is your goal to establish common vocabulary or historical accuracy what Luhmann intended the word to mean?
I am a Zettler
I would like to find out if such an intention existed and if available to follow her. To use that as a basis to establish common vocabulary would be the right thing to do, in my mind. But that's just me.
It also would be quite cool to find out, if one can even understand the mutterings of some of those active in the field.
Luhmann did not mention the term in his essay. So, the answer to your question of your initial post is "No. Nobody can define you the term in the sense of Luhmann" (Perhaps, he used the term in an interview? But then we could argue if he had a clear definition)
The only hope for an "official" definition is in his own Zettelkasten, as far as I know.
I am a Zettler
Thank you for that answer, @Sascha.
Uhm, so that would mean it's not a technical term, at least not yet. Be-cauhseh, because, because, because, the main protagonists of the field as of yet, do not use it as such.
Mhm.
Speaking as a native speaker then, I would say that it is obvious just a connotation for "the slip that comes afterwards." In a general sense.
At least that's how I found it used in Niklas Luhmann – 2016 – Ich denke ja nicht alles allein (Zettelkasten als Zweitgedächtnis) - YouTube and this corresponds with my linguistic sensibilities.
Here is something I found online:
"Anschlussfähigkeit" der Zettel zu erreichen. Den Begriff "Folgezettel", so wie er als Funktion
im ZKN3 verwendet wird, finde ich hier irreführend.
Integration einer vereinfachten Ordnungsstruktur nach Luhmann · Issue 145 · sjPlot/Zettelkasten · GitHub
JonahSeng goes on:
But Lüdecke advertises "Zettelkasten according to Luhmann" which it is clearly not. You would at least hack according to the way of Seng to make it so. And even then it's still minorly different, as Seng clearly puts it.
I see that you said this elsewhere:
@Perikles would you consider providing examples of how you use sequencing as a numbering scheme? I ask because I am interested in how it fits into the toolset we have available for interacting with our Zettelkasten. My questions would be along the lines of:
Now that I ask this maybe you might open a separate discussion with your presentation and details? I think I would greatly benefit from your insight and experience.
In the meantime, I am going to track down what the Luhmanisch numbering scheme is all about.
🤦🏻♂️ I am so unfocused. Luhman-isch, I get it now! That went right over my head.
Technically, a Folgezettel (the "1a" to the "1") would be best translated as parenthesis Zettel or something a long the line. The description of in the article goes more a long the line that the 1a to the 1 is more of a dependent clause to a main clause.
One could develop a theory on his exeptionally bad writing style: With his Zettelkasten he didn't got into the habit of putting the most important parts of his sentences into the main clause but didn't discriminate main and depended clauses.
I am a Zettler
@MikeBraddock:
I tried out several things. At one point I had a A5-PDF based Zettelkasten, because that would allow for drawings in conjunction with text, but it didn't really work. I used org-mode and also Markdown. But these formats went on my nerves after a while. Suddenly you can't use a "#" or a "*" or something, without getting a bad conscience.
But I settled on HTML, having a local website basically. You know, the web, the world's Zettelkasten. I figured, it's what it came to on this planet, why not just use that stuff?
If I ever wanted to develop software for my ZK, I'd have all web technologies at my disposal. I also love that I am browsing my Zettels in my web browser.
Yeah, I use the scheme Luhmann invented. Regarding the Zettelkasten-fu I wanted note sequences and in terms of encoding I couldn't find anything that would top Luhmann's scheme. I tried out several ones (I still have a backlog of several old Zettelkästen… oh, oh, oh…)
The filenames of my .html or image files are all beginning with the Luhmann number and then a "slug" derived from the title. I try to keep them CLI and script friendly. So underscores for spaces and so on. (Although this grinds my Macintsoh DNA, but you can't have everything in life…)
I don't use UIDs, the filenames are UIDs. How could they not?
Several other posters have mentioned their (past) use of Douglas Barone's FSIM methodology. I was there, too. @ctietze @John
What I kept from that phase is the "low-tech" notion and to keep everything file-system based. So, my Zettelkasten is easily browsable from both the Finder with Quick Look and the shell.
Also, in that discussion was mentioned the importance of fast filing. This is of less importance with a Zettelkasten, but I still like this "optimization for laziness" as a principle. Here is were the note sequencing shines:
Navigating the "Luhmann-tree" does work and is fun. I will probably code a small CLI tool for it, remains to be seen. I don't know if I gained some "insight" doing so that I wouldn't have discovered if I used structure notes exclusively.
So. My Zettelkasten is still under 1k Zettel, so I cannot speak to some of your questions, not really. My hunch is, when you are around 3k Zettels you are "there" and can say something.
Everything under 500 Zettel? Should work with any scheme, it's just a bunch of files with stuff. You will find something if you'll grep it…
At this point I can say this, though, the main point of all the stuff that @Sascha drove home here, avoiding the collectors fallacy by writing Zettel instead of copying a pile, that is where the whole thing already payed off for me. My head feels better for it.
Nevermind your numbering scheme…
Thanks for asking, man!
@Perikles
Bravo. I love how you have rolled your own. I also see and hear your enthusiasm for what you have done. Very exciting. Low tech but high usability and flexibility. I also like how you took what you had available and built what you needed. Conventions. By being clever and following conventions people can do interesting and amazing things. Your set up clearly shows that as well and ingenuity.
You have helped me validate and understand that there are ways that "sequencing as you go" can be of great use and benefit. This and your LISP explanation in the other discussion was quite beautiful.
In my previous life, as a developer, I generally found that when you roll your own approach, there is a tendency and often a need to fiddle and tinker. In some cases, the rate of fiddling and tinkering exceeds the rate of using. Have you found that to be true with your approach? Have you reach the set it, forget it, and just use it point?
Thank you very much for answering my request.
I can't say it any better then that.
I find this an extremely helpful and important part of using a zettelkasten. In my opinion, this aspect is massively neglected. Most systems opt for an yyyymmddhhmm ID. Such an ID loses the whole tree of connected notes and note sequences, certainly at a glance. I also emphatically agree that thinking about where the note should go in the tree is an important part of the work. Using such an ID as Luhmann demonstrated allows you to see your clusters and knowledge tree.
Can I ask why The Archive, and most other note taking apps have opted for the date-ID for zettelkasten?
There are lots of discussions about this topic in this forum already, blog posts on the main site additionally. There is not a short and simple or definitive answer to this question. It would require a lot of effort to summarize here. This thread is also not the best place to discuss this question.
You can decide for yourself which ID you want to use. Are you already using a Zettelkasten, starting one or consider changing an existing Zettelkasten?
AFAIK the best software available to use with Luhmann ID is ZKn3.
Luhmann ID and timestamp ID are not so much different from another. They are both unique identifier with additional information embedded into it. In both cases you have a sequence, in both cases you have to branch off to stay organized. You can use either system to form note sequences. You can also use either system for any form of organization in your Zettelkasten.
Keep in mind though that Luhmann ID embedds a path to its UID, for example
1,1/1aor1/1a/1b. This limitation is extremely helpful for the reasons you mentioned, but also requires more complex solutions to overcome these limitations. A timestamp ID is a more generic approach that can be adapted by anyone.my first Zettel uid: 202008120915
Thank you @zk_1000, that's extremely helpful. I have since read up on the various discussions. Am I right in assuming that those who opt for a date ID structure their notes via structure zettels that would show the hierarchy or positional connections? Would this mean that if you would in a physical ZK place note 3 behind note 2, with a date ID you would just link note 2 to note 3?
Yes. It is a list view to show the sequence, in a text file. But the same is true for Luhmann ID. ZKn3 for example does not use date time ID. It shows the sequence as an indented list of notes. Using Luhmann ID if you order your files by name in a file browser you also get a list view for the sequence.
Yes, note 3 is positioned behind note 2. You can do this with a physical or a digital ZK, using Luhmann ID or date time ID.
This discussion could be of interest to you: luhmann-ids-vs-date-time-ids, especially this comment and this comment, among others. It states there that time stamp ids require additional effort to connect notes and also illustrates the challenges of using Luhmann IDs.
my first Zettel uid: 202008120915
Luhmann's method created an intermediate structure that is often misunderstood or missed.
People often think his structure was like this:
But his actual structure was like this:
The Lines of Thought structure was created primarily through the sequential/branching IDs and the sequences emerged naturally from his system, bottom up, as he performed his research. One can visualize his physical Zettelkasten as consisting of a set of card sequences, some large and some small, each constituting an overarching theme or line of thinking among several authors over a particular period of time. These were the folgezettel. Author A put forth an idea, then later author B built on the idea extending that particular line of theory, then author C built on what A and B had discovered and extended the theory. This is all one line of thought. But author C also built on authors P and Q who were working in a different but related field with their own line of thought sequence of notes in Luhmann's Zettelkasten. This was denoted by a reference of the Luhmann ID from C's note to P/Q and vice versa, with a brief statement of why they were connected.
This was important to Luhmann because his chosen field of inquiry (academic sociology) was based on these lines of thought and required tracing one's own ideas back to these lines of thought.
We can track these lines of thought in at least two different ways:
The latter is probably more amenable to a digital system.
In both ways they form the same structure. It is not hierarchical, but rather, a flat structure. The latter has the advantage that it is possible to show the connection for C's note to P/Q directly as well. In a physical ZK you would have had to make a copy for every sequence the note is being part of, which is impractical. In a digital system you can effortlessly generate as many copies as needed.
An hierarchical outline would form another structure.
my first Zettel uid: 202008120915
I may not have been clear, but my second bullet was essentially intended to describe using a hierarchical outline to track the lineage of ideas.
Either approach can be used, and both require maintenance effort. The Luhmann-style ID requires effort in creating and maintaining the ID system during note creation. The outline approach requires updating one or more additional notes each time. There are pros and cons to each approach just as there are pros and cons to the timestamp ID approach.
If one's line of work leans heavily on tracking and reciting the lineage of particular ideas and theories then it may be worthwhile to investigate one of these two approaches.
Personally I would opt for the hierarchical outline approach because it enables me to add surrounding contextual text to the entry in the outline (since it is just a series of bullets inside a note). It also enables me to reference the same note from multiple outlines to show how a particular author builds on multiple other lines of thought and in turn spawns multiple different lines of thought.