[Plugin] New Same-Level Note: automation of the folgezettel filenaming approach

This is one of two plugins for The Archive that automate the folgezettel naming convention.
The New Note plugin produces a note within the current sequence of notes.
The plugin looks for the Folgezettel ID in the filename, extracts it, and creates a new note with the filename based on the current note, selected in The Archive.
It also creates a heading of the level 1 with the Folgezettel ID.
Post edited by ctietze on
Howdy, Stranger!
Categories
- 3K All Categories
- 152 Research & Reading
- 692 The Zettelkasten Method
- 8 Knowledge Work
- 100 Writing
- 464 Software & Gadgets
- 154 Workflows
- 730 The Archive
- 15 Plug-In Showcase
- 88 Resolved Issues
- 225 Projects Logs and Journals
- 83 Project: Zettelkasten.de
- 53 Critique my Zettel
- 171 Random
- 373 Introduce Yourselves!
Comments
How would you work in the note title?
I am a Zettler
Hello Sascha,
Usually, the title is the last thing I formulate in the note. It means I have a rough draft of an idea for the note before I dive into formulating its content. So, the moment I use the plugin, I have an idea of the place the note should be attached.
I hope I have interpreted your question right. Please don’t hesitate to adjust my reading of your question.
I'm planning to describe the plugin algorithms at greater length later.
Ah, got you.
I am a Zettler
I have updated the plug-in and added a thorough description of its functionality.
The previous version of the plug-in implemented a different approach to the alphabetical values of the Folgezettel ID. That approach caused the sorting inconsistencies, exemplified in the extreme cases when the alphabetical part of the existing Folgezettel ID ended with a
zcharacter and the next alphabetical value would beaa, so the new note went afteravalue and appeared earlier in the sequence.The current plug-in version implements another logic in the same extreme case it adds an
avalue to thezvalue, so the following thezvalue becomeszain this example.The New Note plug-in release of the 1.1.0 version is available on the same GitHub page.
The new description of the plug-in is presented below:
The New Note plug-in is supposed to work in a Folgezettel-based Zettelkasten.
The plug-in ignores any occurrences of Citekeys as
Baljeu1974or Timestamp IDs as202412291635in the filenames. It extracts the Folgezettel ID from the selected note’s filename. Then the plug-in compares the extracted ID to the rest ones presented in the filenames to generate the next available Folgezettel ID of the same level as the one in the selected note’s filename.The plug-in will extract Folgezettel ID from any position in the filename, assuming
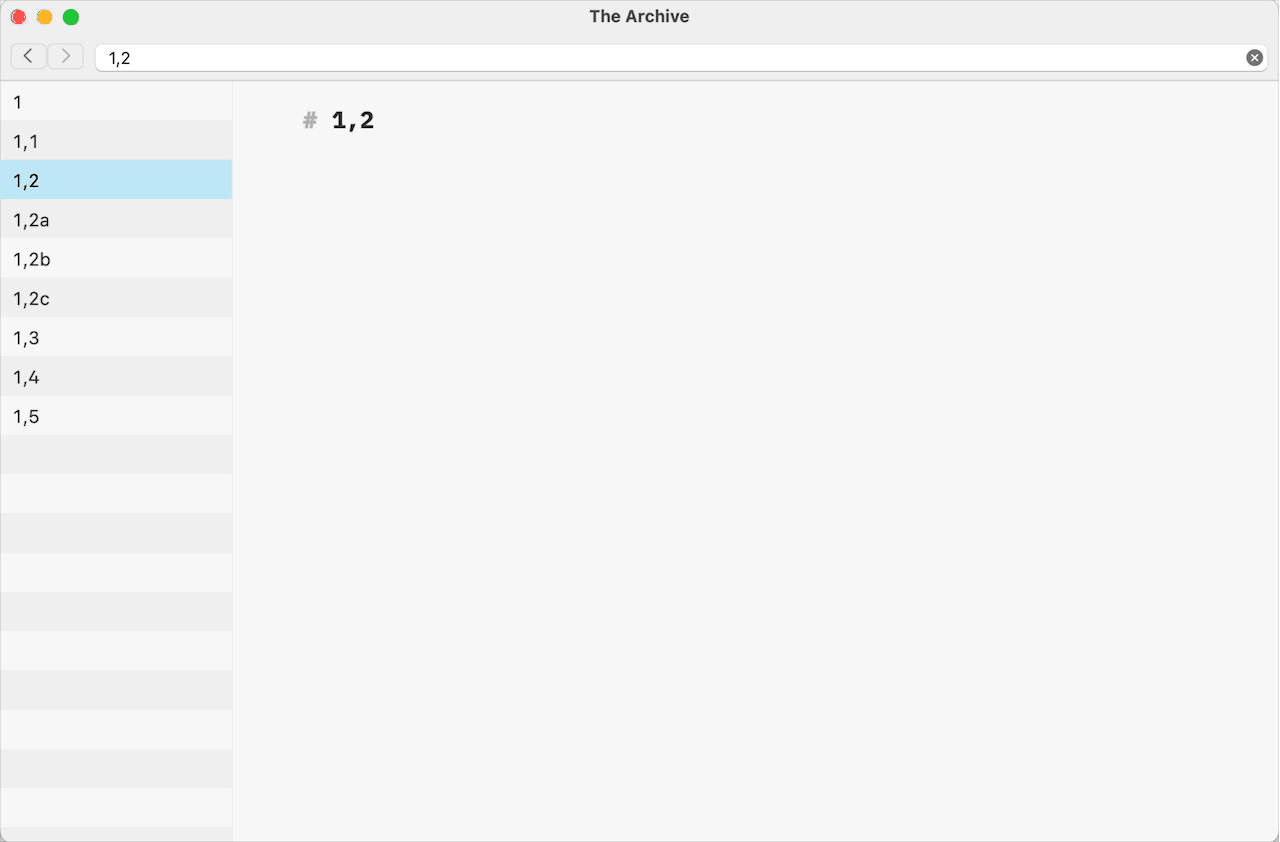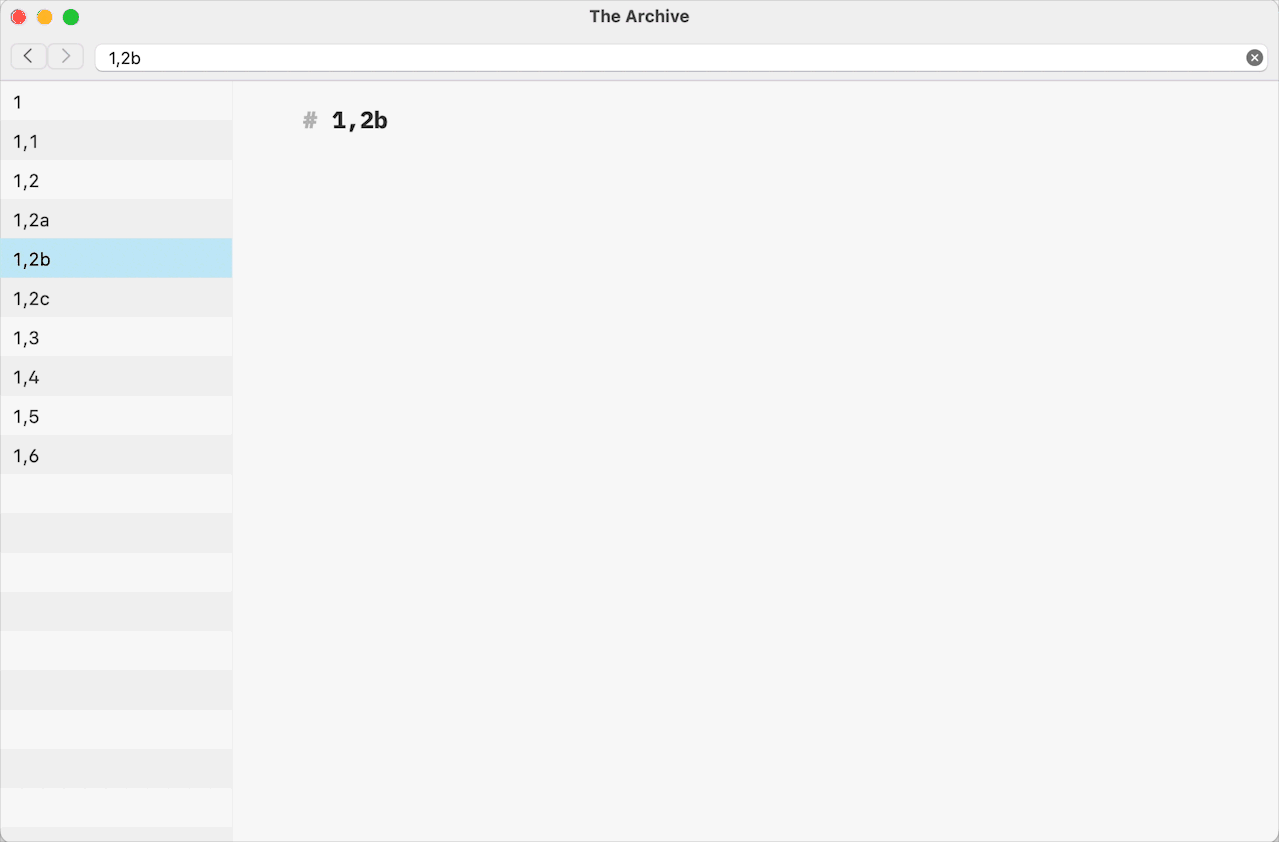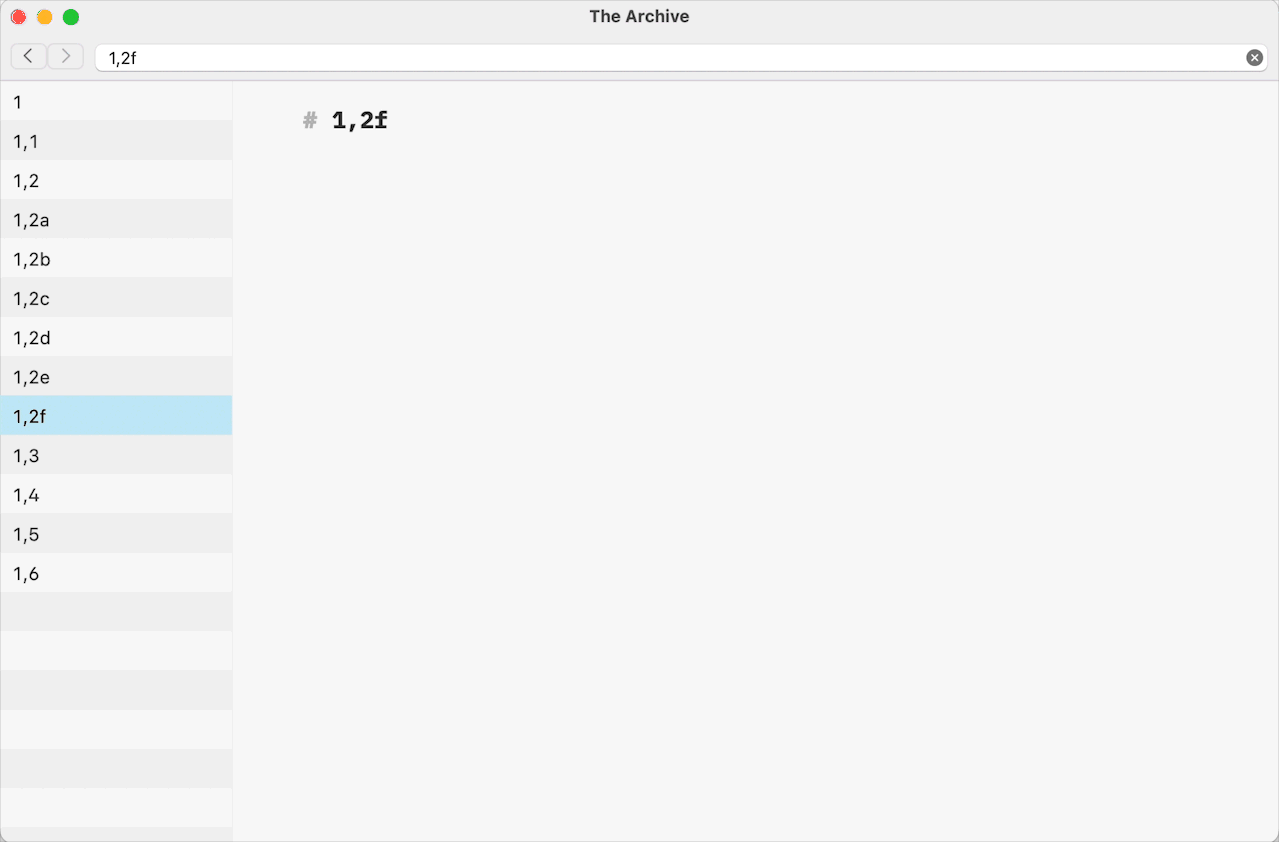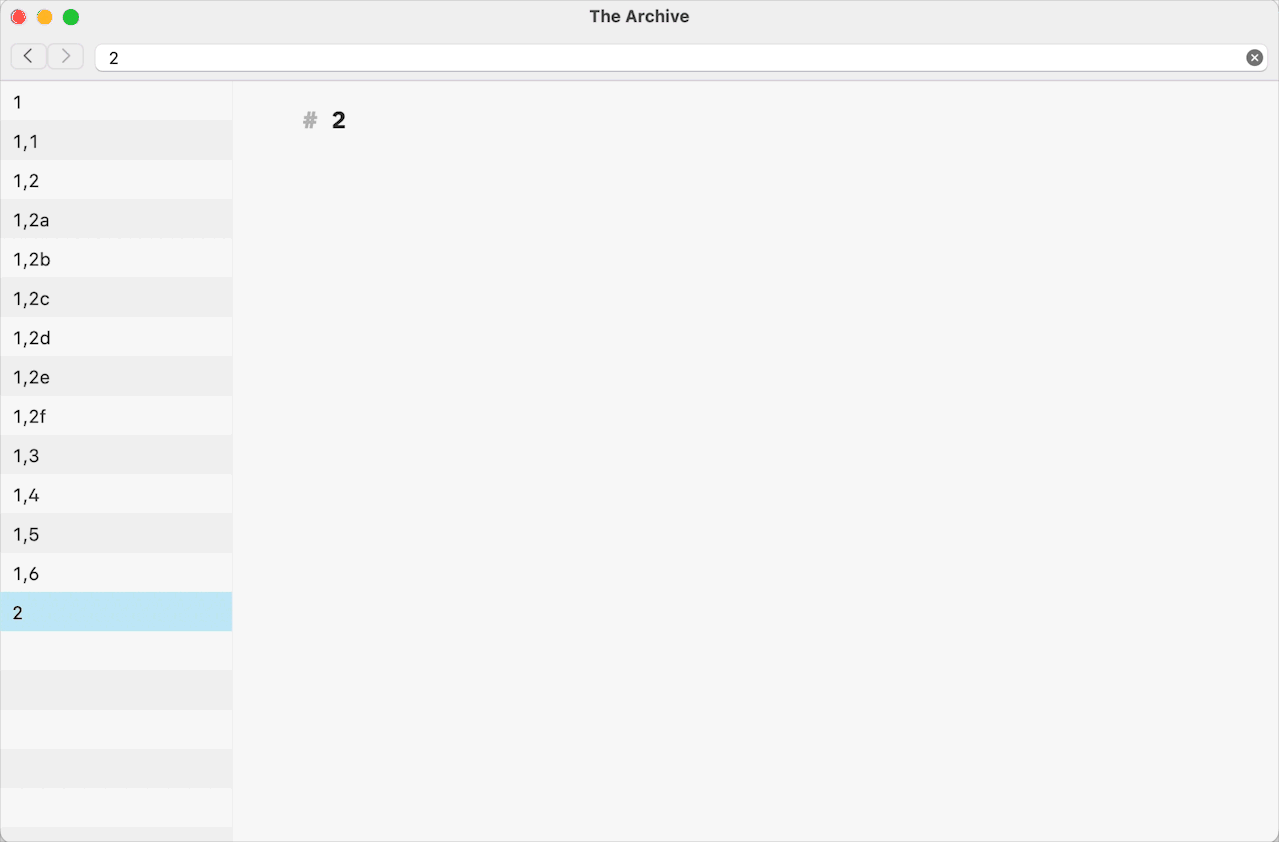
1,1a Note name,Note name 1,2c,Note Name 1,3f with additional information in the filenameas possible examples. The plug-in will ignore and won’t extract a Folgezettel ID if the selected note filename contains a Timestamp ID or a Citekey.The following list of notes’ filenames is the basis for the description of the plug-in algorithms.
11,11,21,2a1,2b1,322,12,1a…2,1zAssuming that the selected note has a filename of
1,2a, the plug-in will create a note with1,2cfilename and theH1 levelheading with the new Folgezettel ID in its body.For the filenames ending with the digital part of the Folgezettel ID, the plug-in creates the next available Folgezettel ID of the same level, following the same logic as with the alphabetical parts. For example, the filename
1,2will result in the note with the Folgezettel ID1,4, and the filename2gives a Folgezettel ID of3.In the extreme cases, when the alphabetical part of the Folgezettel ID ends with the
zcharacter as in the example of the note2,1z, the next Folgezettel ID is generated by adding anacharacter to the initial alphabetical part. The exemplified Folgezettel ID2,1zwill become2,1zabecause2,1zexists in the exemplified note list.Both plug-ins sound similar-ish and it's not easy to see what each one does, and does differently. "Sequence" in the other one is maybe not enough: this one seems to add a sibling on the same level (1,1→1,2) while the other creates a new child note, one level of hierarchy deeper (1,1→1,1a).
Maybe "sibling" and "child" are useful terms to distinguish both?
Author at Zettelkasten.de • https://christiantietze.de/
Hello, Christian,
When I was deciding how to call the plug-ins I sticked to the terminology of the Zkn³ application, assuming those terms are more suitable and widely-used ones within English-spoken community. As for me, the “sibling” and “child” terms are more characterizing ones. The “New Sibling Note” and “New Child Note” names for this and the second plug-in, respectively, are more appealing to my eyes as well.
Before giving the plug-ins these new titles, I would like to know whether the terminology of “sibling” and “child” is related to the Folgezettel naming approach in the English-spoken community.
I think a better approach to the naming of the plug-ins would be to keep their titles as descriptive as possible, so I will rename the “New Note” plug-in to the “New Same-Level Note” and the “New Note Sequence” plug-in to the “New Lower-Level Note.”
Sounds reasonable to me, too!
Author at Zettelkasten.de • https://christiantietze.de/
I don't know proper terminology in this context. I believe that same and lower is opinionated on how a sequence is displayed.
I prefer sibling and child notation. How about follow on note and branch on note? Or maybe extend sequence and branch on sequence?
my first Zettel uid: 202008120915
I would like to keep the names abstract and to avoid secondary connotations in them. Siblings and child terms or branches analogy bear literal imagery in themselves despite the fact the terms relate to the field of data structures. The relation to the tree-like structures is concrete as well, and in this way it is similar to the connotations I meant above. So I have chosen a more abstract term of level.
The names are changed.
The New Same-Level Note plug-in release of the 1.1.1 version is available on the same GitHub page.
👍 I renamed the discussion accordingly!
Author at Zettelkasten.de • https://christiantietze.de/