Why the Single Note Matters

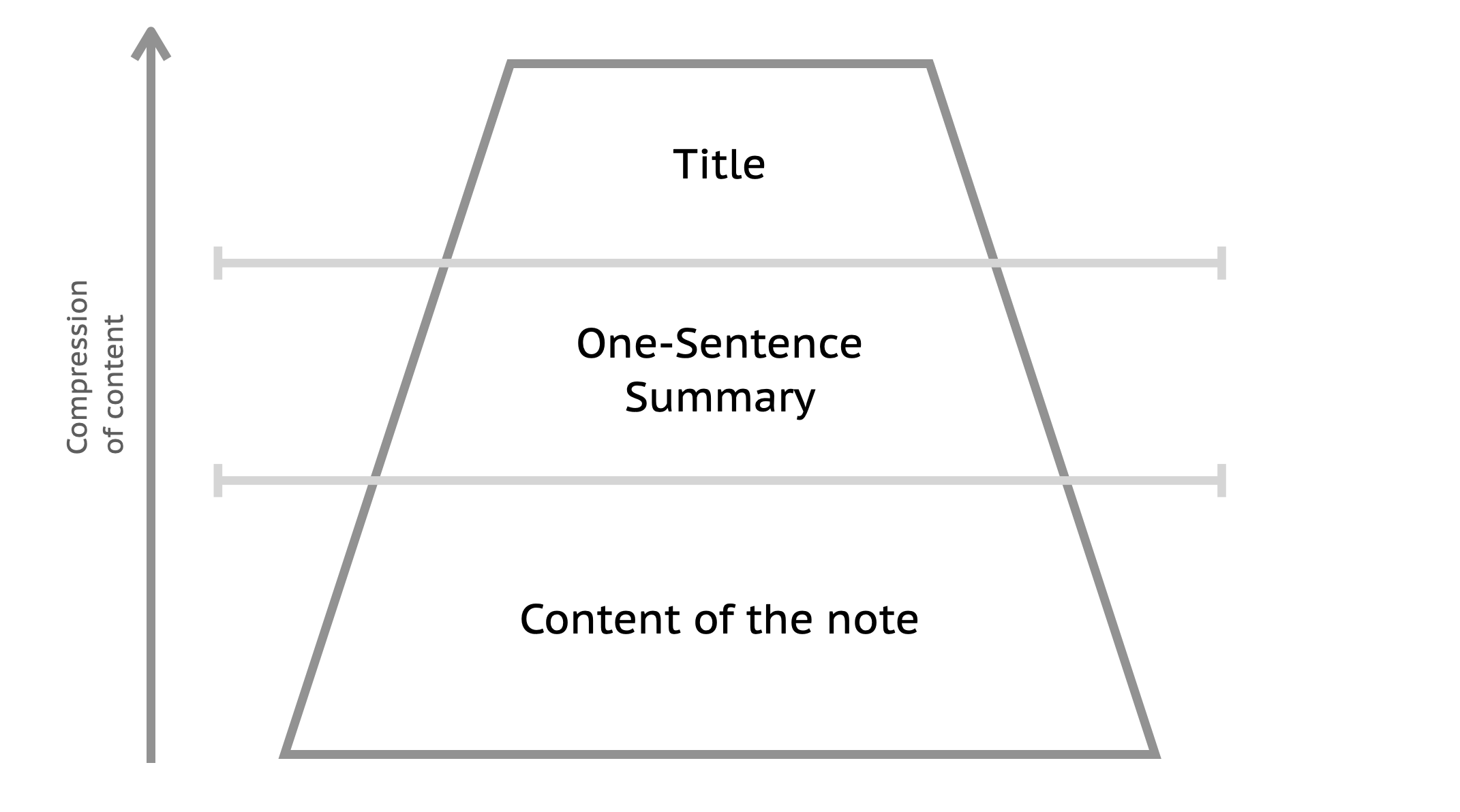 Why the Single Note Matters
Why the Single Note Matters
A Zettelkasten is a personal tool for thinking and writing that creates an interconnected web of thought. Its emphasis is on connection and not mere collection of ideas.
Howdy, Stranger!
Why the Single Note Matters
A Zettelkasten is a personal tool for thinking and writing that creates an interconnected web of thought. Its emphasis is on connection and not mere collection of ideas.
Comments
This makes me think of a note I have about what is worth taking notes on while reading. With one end of level of detail being just the title of the book and the other end copy-pasting the entire book into ones vault.
@Sascha wrote:
Here is a thought that came to mind when I read this paragraph: This kind of analysis-through-refactoring was also one of the key features of the qualitative data analysis software NVivo (formerly called NUDIST—you can imagine why they changed the name). For example, compare @Sascha's passage above to the following paragraph from Tom Richards & Lyn Richards (1991/1992), "Database organisation for qualitative analysis: the NUDIST system", in Papazoglou, M. P. & Zeleznikow, J. (eds.), The next generation of information systems: from data to knowledge: a selection of papers presented at two IJCAI-91 workshops, Sydney, Australia, August 26, 1991 (pp. 116–133). Berlin; New York: Springer-Verlag.
In other words, in the 1980s the developers of NUDIST/NVivo were trying to improve on earlier code-and-retrieve qualitative databases by facilitating the creation of theory from qualitative data through analysis-by-refactoring. Methodologically this seems similar to what @Sascha is advocating.
From what I understand, there is yet a further stage of compression above title, which is Keyword. It seems that Prof. Luhmann went to extraordinary lengths to craft a couple of Keywords for each zettel i.e. they were meant to capture their essence. Would my thinking be correct?
I don' think so:
I am a Zettler
Thanks for the clarification, I was mistakenly under the impression that all zettels had keywords..... Will review my process - Thanks
@Carriolan
I use tags quite a bit in my ZK. One thing I noticed, and I believe it is a problem with keywords as well, is that you very quickly have so many zettels with a particular tag that the tag becomes meaningless. That is, you search on a tag and get 30 or 40 zettels - that doesn't help when you are looking for a specific zettel or even if you are just browsing your ZK.
So, I have one self-imposed rule - a particular zettel can have no more than about 5 tags. I regularly look at my list of tags and if I see one associated with more than 5 zettels, I break that tag into two or three tags, each more specific, associated with fewer zettels. As a result, my tags tend to be formed of two or three words - a main word and then one or two modifiers.
For example, I do a lot of work in water resources, specifically on dams and canals. I could have a tag "#Dams", but that would be associated with 30 or so zettels. So, in the process of becoming more specific, I have the tags "#Dams_design", "#Dams_construction", "#Dams_monitoring", "#Dams_maintenance" and "Dams_regulations", each with only a few associated zettels.
One side benefit of this approach, if I follow it consistently, is that my list of tags not only provides very specific entry points into my ZK, but also becomes a de facto index (without page numbers, of course).
Thanks, this is useful. I have been considering nested tags e.g.
#Dams/Design. Do you think that this is viable or have I missed a fatal flaw?For me, tags are most helpful when I‘m using them to define "search contexts". I.e., the goal for a tag/keyword is NOT to retrieve a single (or just a few) notes. Instead, by assigning a tag to a note I‘m stating that the note belongs to a certain context/topic/concept/etc.
Searching for a certain tag then brings up all notes that belong to the corresponding context/topic (or, when searching for a combination of tags, the subtopic or, say, the cross-section between two concepts etc). You can then continue to perform a regular search within this subset of notes.
This has also been discussed here:
https://forum.zettelkasten.de/discussion/comment/15106/#Comment_15106
@msteffens Long time no see.")
Do you use structure notes? And if yes, how do they interact with your tag functions?
I am a Zettler
@msteffens
I started off with the concept that you expressed, and I sometimes still do searches on multiple tags looking for intersections, but I found I just didn't like having tens of zettels associated with a tag. Hence my move to make the tags more specific.
@Carriolan
I don't think The Archive works with nested tags, at least not in the way that Bear does. So it probably doesn't matter if a tag is "#Dams-Design" or "#Dams/Design" - you still get the same result in The Archive. If you are also reading your ZK markdown files in other software, then the second form of the tag might be more useful in producing a nested structure.
I could accomplish what I do by following @msteffens suggestion and instead of making more specific tags, adding "modifier" tags. For example, "#Dams-Design" would become "#Dams" and "#Design". I could then find the same subset of zettels by searching on "#Dams-Design" in my actual ZK or searching on "#Dams" and "#Design" together, in my hypothetical alternate ZK. To me, this is inefficient and also somewhat vague, because neither of the last two tags actually specifies what the zettel is about and the second of the two, "#Design", could apply to many other concepts that have nothing to do with dams.
Finally, the side benefit of using my list of tags as an index to my ZK was both unexpected and welcome. For me, it creates a situation where I rely less on Structure notes and more on tags, to find entry points in my ZK. I eventually get around to creating Structure notes, but I prefer to do that later in the process, rather than up front, as is the practice of other zettelnauts on the forum. The structure of my Structure notes is thus less pre-determined (with built-in biases) and a little more organic than it otherwise would be.
This is one of those situations where we try different approaches to organizing our ZK, and eventually settle of something that fits how we think and work.
@GeoEng51
Thanks for the explanations. I agree that the tag "#Design" just by itself is very broad and might be misleading. However, a note having both tags ("#Dams" and "#Design") would sufficiently indicate for me that the note is about the design of dams. And combining high-level tags helps me to better reuse my tags.
@Sascha wrote:
My use of structure notes mostly depends on the time available for reading / knowledge work (which is often scarce).
Recently I've resumed reading a book about mountaineering & climbing. There, I'm using simple overview (aka structure) notes to mirror the book's chapters.
I tag my overview notes similar to my regular notes, i.e., I add topical keywords (in MultiMarkdown format). In addition, I add an organizational
:overviewkeyword which I can use to gather all my overview notes.The narrow leftmost column in the first screenshot below shows my list of keywords restricted to only those keywords whose notes also contain the
:overviewkeyword. I.e., this view just shows all the keywords (topics) from my overview notes in that document. This list of overview topics can serve as a nice entry point into my notes.Note that I've selected one keyword ("Eis" = "ice") which usually would cause the main notes list to display all notes for that topic. However, by also searching for
:overviewin the main search bar, I only get all my overview notes for that topic.The result of the above is not much different from searching one's notes corpus for
@Eis AND :overviewbut the above allows for more exploration on the way.In a similar fashion, I'm also often "filtering notes by other/overview notes":
In the second screenshot below, the leftmost column just shows notes containing the
:overviewkeyword. I.e., it lists all the overview notes in that document.I've selected an overview note about knots ("Bergsteigen ... > Knoten"). This causes the main notes list to only display notes that are mentioned within that particular overview note. (this is what I mean by "filtering notes by other notes").
Finally, in the main search bar, I've done an OR-search (
@Spierenstich | @Kreuz) which further restricts the notes list to notes matching these keywords.So both, tags/keywords and overview/structure notes, work together to filter my notes corpus.
Many thanks for your explanations!
If I may ask a follow-up question: What would you consider your thinking canvas? I, obviously, use structure notes for that, since I treat them just as paper and shuffle the content around. I can't figure out what would be the equivalent in your ZK.
I am a Zettler
The above book reading examples are mostly about processing information (and structuring it so I can recall it easily later). So simple stuff, but that (hopefully) helps to illustrate the process.
If there‘s more thinking involved, I‘d also make use of independent structure notes (not tied to a certain publication), augmented by the visualization of their connections. I also tend to open the (structure)notes I‘m currently working on in separate windows and arrange them on my second monitor as I see fit. Later, I may preserve that ad-hoc clustering via a structure note, or simply via relations in an individual note.
I‘ve thought about an editable visual canvas. And, in case of working with a single structure note, I’ve considered a (synched) outline view to build & (re)arrange the note‘s hierarchical outline of comments & linked notes. But this isn’t fully thought thru, may generally be tricky to get right and thus has to wait.
I am wondering if your background in ecology is the basis of your way of working. To me, it is very strange to have a distributed canvas ("augmented by the visualization of their connections").
I keep being fascinated by your ZK.")
I am a Zettler
I despair of ever attaining a small fraction of the impressive work here.
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.