Quick insertion of tags with type-ahead search (using Keyboard Maestro)

Yet another Keyboard Maestro tweak that works fine with The Archive. It is a variation of the type-ahead-linking-macro described over there.
Use case: If you have a serious amount of tags you will might get in trouble figuring out which ones already exist and how you spelled them exactly (caps? CamelCase? singular?). Wouldn't it be nice to have an (automatically updated) list of all #tags you use in your Zettelkasten and could easily insert them everywhere.
Keyboard Maestro to the rescue: This workflow requires two macros. One will keep an eye on your tags an occasionally collect them, the other uses the collection for a convenient search bar.
The Tag Collector Macro
This macro uses a piped series of small shell commands to extract all the tags from the files in the archive folder.

A short rundown:egrep -ohws "\B#[a-z][A-za-z0-9_-ÄÖÜäöüß]+" *
This part does the searching. It searches for everything that starts with a #.
The [a-z] matches a lower case letter. Why? I insert this step to exclude some false matches. In my archive I have a lot of HEX color codes like #F0F0F0 - I always write those with uppercase letters and all my tags start lower case. I also have quite an amount of #1, #2, #n's appearing in my notes which are also not tags. This little restrictions sorts out an resonable amount of "false tags". If you have other tagging habits, simply remove the [a-z].
The sequence [A-za-z0-9_-ÄÖÜäöüß]+ defines all the characters that can occur in a tag. In my case: all letters, numbers and a few special characters an umlauts. Add yours to this collection as needed.
The second part sed /^[^#]/d| sort | uniq removes duplicates, sorts the list, and does a little additional clean up.
Keyboard Maestro saves result in a variable for later use. The macro needs a trigger to update the list and include new tags. Keyboard Maestro provides a lot of trigger options. For my needs "At login" is frequent enough. But you might also consider "At system wake" or "Periodically" or at fixed times.
The Tag Selector Macro
This does not need much explanation. It is basically the same logic as in the note-link-macro. Make sure you use the same variable name as in the collector macro in the first step.

If you give this macro a global shortcut, you can access your tags everywhere on your system.
A screenshot of the result, that is: the tagbar in action:

Please note: In my case, I still have a few false positives left: non-tags appearing in this list. As long as it is a small number, I don't mind them. But of course you could optimize this further.
You can download the two macros from my Dropbox: The tag collector macro and The tag selector macro
Enjoy,
Roland
Howdy, Stranger!
Comments
Sweet! Now I can defer implementing tag auto-completion a while longer
I'm amazed that Keyboard Maestro can store the result of one macro execution for later, didn't know that. The possibilities! Working with a folder of plain text files as the primary store really paid off quickly when I see this. Great stuff.
Author at Zettelkasten.de • https://christiantietze.de/
Hi Roland,
Again, very cool and useful macro. Unfortunately, I can't seem to get the macro to work. When I copy and paste the search line "egrep -ohws "\B#[a-z][A-za-z0-9_-ÄÖÜäöüß]+" *" into my terminal window (in the correct Archive folder), I get the following error "egrep: invalid option --". Unfortunately I have no idea what's causing this error (in part because my unix and regex skills are negligible). Do you have any insight?
Thanks,
Eric
Wow AGAIN. Very impressed. Now to see if I can get this to work.
Also @ctietze -- slacker. ;-)
-apoc527
This is Me
Did you set the directory to where you have your notes stored? By default, the macro works with a path of ~/Dropbox/zettelkasten but that's not necessarily a common location. I had to set mine to where I store my notes (which for paranoid security purposes, I will not share). Then you'll have to run it once, since it only runs on Login by default.
Edit: Duh, I see that you did that part. Not sure then!
-apoc527
This is Me
@EricB The quoted part works on my machine. I don't seem to have anything fancy installed. What output do you get for
egrep --version?Author at Zettelkasten.de • https://christiantietze.de/
I love what you are doing! I currently only have about 25 "approved" tags that I use, and a scheduled Python script warns me whenever my notes contain a tag that is not on that list. So I first wasn't sure how useful this macro would be to me personally, but it turned out, even just for quickly inserting one of my tags, the macro is really convenient.
I think there are two typos in the regular expression:
1) The second bracket is supposed to start with
A-Zinstead ofA-z.A-zmatches a bunch of unwanted stuff like "]".2) The
-character has to be escaped (and apparently moved to the end, at least with egrep). Currently you are matching the range "_" to "Ä".So the revised command would be:
egrep -ohws "\B#[a-z][A-Za-z0-9_ÄÖÜäöüß\-]+" * | sed /^[^#]/d | sort | uniqThere is, however, another aspect about that pattern that can be improved. The
\Bat the beginning allows for a bunch of false positive matches. For instance, if your notes contain a link such as "https://www.macstories.net/stories/ios-11-the-macstories-review/10/#dictation", then "#dictation" will erroneously get identified as a tag.In my option, a tag either needs to be preceded by some kind of white space character or it needs to be at the beginning of the line. So instead of matching any kind of word boundary, we would use
(?:^|\s). This gives us:egrep -ohws "(?:^|\s)#[a-z][A-Za-z0-9_ÄÖÜäöüß\-]+" * | sed /^[^#]/d | sort | uniqWith this stricter matching in place, you can also easily prevent things starting with "#" from getting identified as tags, by putting e.g. a dot right in front of the "#". For instance, I have a tag overview (and brainstorming) note that contains all my tags in ".#myTag" form, so they don't get identified as tags by my Python script and by 1Writer.
I hope you find these suggestions useful. I'm a huge fan of using Keyboard Maestro to extend the existing functionality of an application, and I really like both the macros you are creating and the way you are presenting and explaining them here on the forums.
Addendum:
I was just about to post the above text, when I realized that I had not refreshed the thread in a while and there have been new posts...
@EricB: In all likelihood, you have a file name that starts with a
-and that throws off egrep because the file names matched by*are treated as arguments. To prevent this from happening, we can add--before the asterisk to let egrep know that there will not be any further arguments and that everything matched by*should be considered a file name. The following command should work, even with file names that start with dashes:egrep -ohws "(?:^|\s)#[a-z][A-Za-z0-9_ÄÖÜäöüß\-]+" -- * | sed /^[^#]/d | sort | uniqIt is obscure issues like this one why I usually prefer writing a 20-line Python script over writing a single-line nested shell command.
If you like The Archive's "PrettyFunctional (Basic)" theme, consider upgrading to the "PrettyFunctional (Regular)" theme.
Hi @EricB,
looking at your error message, I wonder if you used one or two dashes before the options
-ohws. At the command line single character options must have a single dash as inegrep -ohws. Two dashes are reserved for "whole-word-arguments" as @ctietze used in his commentegrep --version. Maybe some copy action changed that-to--(the automatic text substitutions macOS provides tent to shuffle in such "helpful" transformations – you can change them in the system preferences under Keyboard > Text)?Most command line tools have both, short and a more verbose form of handing over arguments. This version should be fully equivalent to the short version in my original post:
egrep --word-regexp --no-messages --only-matching --no-filename "\B#[a-z][A-za-z0-9_-ÄÖÜäöüß]+" *- You might try this one.Just to make sure people don't spend more time trying to solve the "egrep: invalid option --" issue: The solution is at the end of my previous post, slightly buried under a wall of text.
If you like The Archive's "PrettyFunctional (Basic)" theme, consider upgrading to the "PrettyFunctional (Regular)" theme.
Hi @Basil,
thanks for your time to (again) improve on the workflow. This is very much appreciated!
You are totally right on the typos and the
-that needs to be escaped.Unfortunately your version of the expressions fails on my files. Some thoughts:
egrep -ohws "(?:^|\s)#[a-z][A-Za-z0-9_ÄÖÜäöüß\-]+" * | sed /^[^#]/d | sort | uniq#so the followingsed /^[^#]/dremoves all tags with a space before them (that were not at the beginning of a line in the original file). You would need another sed step in the pipe eliminating that space from the matchessed -e 's/ #/#/'Tags: #one #two #three .... For some reason only the first tag is captured. The pattern seems to consider the space between two tags only once and does not match the second. The\Bseems to solve this - with your caveats (and, as I just discovered it also fails if the tag starts a line - *sigh*)This would be a lot easier if egrep would support positional assertions. Maybe I'll rework the macro and do all the cleaning up directly in Keyboard Maestro.
Roland
Thanks to ALL for the comments and suggestions.
@Basil was correct- I had a file name that started with a "-". I changed that and now everything works like a charm. What a friendly and helpful community here! And thanks again to @kaidoh for sharing these keyboard maestro applications.
Cheers,
Eric
My bad for not double-checking tags that are preceded by spaces. The reason why I used
(?:^|\s)instead of just^|\s)was because this non-capturing version makes sure that a preceding space is not included in the match... well, at least that's how it's supposed to work and how it does work in my Python script. Unfortunately, egrep seems to have a mind of its own in this regard.So yes, we do need to manually remove the space... actually, we better remove all possible whitespace characters from the beginning of each match using
sed -e 's/[[:space:]]#/#/'.It didn't make any sense to me that multiple tags in the same line were not getting matched by my expression. After some experimenting I realized that it was because of the "-w" ("only match whole words") option we were using for egrep, which we don't really seem to need anyway with that pattern. If we leave "-w" out, multiple tags in one line match just fine.
So, the following command (hopefully) handles all the issues that we have identified in this thread so far:
egrep -ohs "(?:^|\s)#[a-z][A-Za-z0-9_ÄÖÜäöüß\-]+" -- * | sed -e 's/[[:space:]]#/#/' | sed /^[^#]/d | sort | uniqOh boy, I think I am ready for a drink now...
If you like The Archive's "PrettyFunctional (Basic)" theme, consider upgrading to the "PrettyFunctional (Regular)" theme.
excellent work, @Basil. You definitely earned that drink :-)
I updated the file so the download link in the original post has the improved pipe.
Roland
Supercool. Thanks! I tried this just now on a very sparsely populated zettelkasten and the
sed /^[^#]/dstep in the pipe aborted the process with "zsh: no matches found: /^[^#]/d". I've removed that step and the macro works great now. What is that step doing? My sed-fu is minimal.@fintelkai it matches line beginnings (
^) that are not a hash ([^#]), then deletes these lines from the buffer.@Basil
egrepwith*(list of all files in the directory) will not work with about 4000 notes anymore (Argument list too long), so I guess we'll need afindbased solution. Also, the[a-z][A-Za-z0-9_ÄÖÜäöüß]part might exclude accents, diacritical marks, and composite UTF characters. I'd try\wor[\p{L}\p{Nd}](unicode letter and number characters).Author at Zettelkasten.de • https://christiantietze.de/
Thank you so much @kaidoh for this.
Thanks so much, @kaidoh for these macros and pointing the Keyboard Maestro. One thing that caught me was my tags start with a capitalized letter and the egrep script specified the first letter to be in lowercase. Took a while to parse in a terminal window before I got it right.
[a-z][A-Za-z0-9_ÄÖÜäöüß]became[A-Za-z0-9_ÄÖÜäöüß]Now it really doesn't matter how I start my tags.
This is a huge help.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
I ran into the 4000+ notes limit of the existing commands, so took a stab at adapting it to use "find". I'd welcome any suggestions. Thanks!
find . -depth 1 -type f -exec egrep -ohws "\B#[A-Za-z0-9][A-Za-z0-9_-ÄÖÜäöüß]+" '{}' \; | sort | uniqGents - this macro works like a charm, but I have one problem. I initiate the macro by typing #, which seems to result in the following tag once I search and hit enter: ##example_tag. Did anyone else not have that problem or are you using a different trigger? Thanks in advance!
Never mind. I found the problem and figured out a work around.
Rather than use a "Hot Key Trigger" use "Typed String Trigger". It will activate the macro after removing the "#" typed string, leaving "#example_tag".
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
I've modified the search string a bit, so it also finds tags like "#öffentlichkeit" (starting with an umlaut):
egrep -ohs "(?:^|\s)#[a-zÄÖÜäöü][A-Za-z0-9_ÄÖÜäöüß\-]+" -- * | sed -e 's/[[:space:]]#/#/' | sed /^[^#]/d | sort | uniq.As long as I don't run the command in Keyboard Maestro (KM), the output is fine (e.g. running it directly in shell). In Keyboard Maestro, the tags are messed up (see link). Anyone running into similar problems? I've no idea how to fix it, since it seems a problem inside KM.
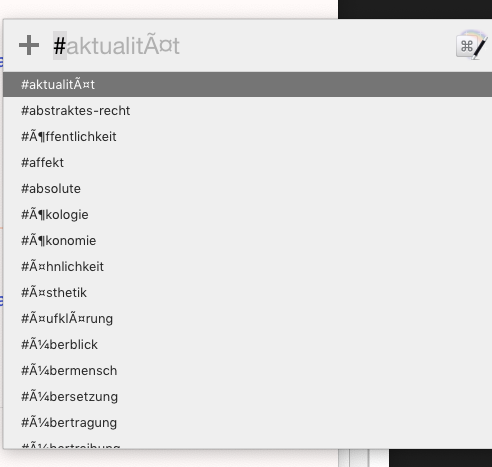
This problem also occurs when using other methods to collect the tags. It seems to be a problem on the handling of variables inside KM. Oddly, the "Insert Link"-Macro works flawlessly.
I've tried to work around it and assigning the value directly to KM; the problem persists.
KMVAR_tmp=$( egrep -ohs "(?:^|\s)#[a-zÄÖÜäöü][A-Za-z0-9_ÄÖÜäöüß\-]+" -- * | sed -e 's/[[:space:]]#/#/' | sed /^[^#]/d | sort | uniq )So I thought, maybe there is some encoding error? So I've tried to force UTF-8 encoding.
cd /Users/ks/Dropbox/Hintergrund/Zettel egrep -ohs "(?:^|\s)#[a-zÄÖÜäöü][A-Za-z0-9_ÄÖÜäöüß\-]+" -- * | sed -e 's/[[:space:]]#/#/' | sed /^[^#]/d | sort | uniq > tmp.tag.collect iconv -f $(file -b --mime-encoding tmp.tag.collect) -t utf-8 < tmp.tag.collect > tmp.tag.collect.utf8 KMVAR_tmp=$( cat tmp.tag.collect.utf8 )The problem persists.
@Henri
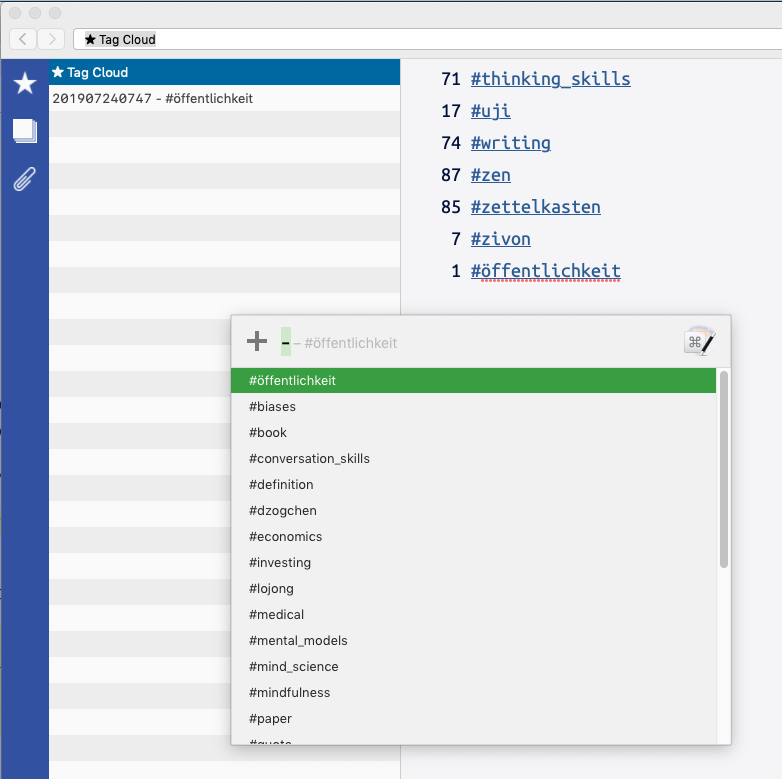
Not sure how to help with this one. On my computer, I don't have this problem. The code
egrep -ohs "(?:^|\s)#[a-zÄÖÜäöü][A-Za-z0-9_ÄÖÜäöüß\-]+" -- * | sed -e 's/[[:space:]]#/#/' | sed /^[^#]/d | sort | uniqworks as espected.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
@Henri Maybe its the match results -- are you sure your original notes are encoded in utf-8? Also, I'm not sure how
LC_ALLandLANG(echo $LC_ALL $LANGin your shell) affect your conversions, but you might want to check these as well.Also, restating my advise from above,
\wor[\p{L}\p{Nd}]could be a better alternative to[A-Za-z0-9_ÄÖÜäöüß\-]Author at Zettelkasten.de • https://christiantietze.de/
Thank you for your replies. Strangely, LC_ALL and LANG were empty, it works now.
Least, not last: Great workflow, thank you again for sharing.
@Henri what did you do to fix it?
Author at Zettelkasten.de • https://christiantietze.de/
I've created .profile (there should have been one already, I guess)
machina:~ ks$ cat ~/.profile export LC_ALL=de_DE.UTF-8 export LANG=de_DE.UTF-8