Assumptions about software implementations of note-to-note links

@sfast's and @ctietze's replies to a comment in this thread made me realize that there is another potentially important distinction that is problematic: unless I am mistaken, TheArchive implements "links" differently than almost all other ZK/wiki software. I don't know for sure because I cannot try TheArchive (Mac-only) and I haven't tried all other options.
You may recall we have been advocating to manually follow links when your app doesn’t allow clicking on them by simply searching for the ID. We ate our own dogfood, telling folks that links are just a more convenient way to perform a search...
And @sfast said:
The Archive imitates links by making everything between double-brackets a search that you can perform via mouse click. That makes this feature replicable with a normal text editor. In fact, I operated my Zettelkasten like this for a long time: Manually copy & paste the ID to follow direct links.
So this means that TheArchive doesn't actually have a function for note-to-note direct links that work the way Luhmann's ZK did or the way that web links or Wiki-links or any other links do. All the others actually link one note to another directly but do not perform other search functions. TheArchive's "links" are just searches for a note's DTID, whether in the title of the note or the note content.
It is only now, after months on the forum, that I understand why screenshots from TheArchive have only the note DTIDs in double-brackets rather than the entire note filename, whereas other software I've tried looks different. Perhaps I am slow.
But the above comments falsely suggest that, because you can copy/paste a UID in other software and search for it in the same way TheArchive automates, that it is ok to analyze workflow with TheArchive in mind as a prototype software implementation. However, this is wrong because it's not the case that the other software is simply lacking TheArchive's function - it is that other software is actually implementing direct link functionality in a different way that is incompatible with the assumptions that a pseudo-link strategy (i.e., TheArchive's search "links") encourages. This difference is important because people using any software that allows direct links will not be putting UIDs in a search bar manually whenever they want to follow a link; they will be clicking the link directly, which has a very different effect.
Sorry if this was obvious to everybody else, but if this is right, then a huge number of comments about whether certain practices are redundant, easy to implement, high or low friction, etc. are being strongly influenced by the significant difference in implementation, and the impact of that is disproportionately high because @sfast and @ctietze are obviously the most experienced and prolific posters here!
Now you may take this observation as an argument that TheArchive's implementation is better than actually using direct links. I think that's a more complicated discussion for another day. But it clearly influences claims about ZK methods.
For example, in the other thread @sfast said that WIDs (i.e. word-only note titles as IDs) are harder to use than DTIDs because:
you cannot ensure uniqueness if you change the title without reliance on software.
Any software that actually implements direct links will rely on reference to a full ID, so in most software (on this point) it doesn't matter whether you use DTIDs or WIDs or LIDs or both. And it is a huge problem to change titles in other software, unless the software has a reference update function. But @sfast talks about changing note titles as if it is common practice because it is not an issue for the minority (or majority?) of ZKers who are TheArchive users. He might be thinking that even if you change the filename, as long as the DTID is the same, it's not a problem because you can manually search the DTID. But people using direct links in other software are not going to do that - they will use that software's linking feature.
@cobblepot: Yes, but I don't understand how DTIDs are redundant or why WIDs are not redundant.
@sfast: Using both is redundant.
@sfast: If you use WIDs you can't change the title. [With DTIDs] Change the title but the DTIDs remain the same.
Using both is not redundant in software that relies on direct links, because each gives different information. DTIDs + WIDs do not provide any "changeability" advantage over just WIDs in most ZK software that relies on direct links.
"202004211548 I am bread" can change to "202004211548 I am not bread" without any problems.
In TheArchive only, right?
Lastly, if the above is right, it also seriously impacts this notion of software agnosticism that has been (rightly) trumpted around here.
@ctieze said:
That's why we put the DTIDs in the file names as well: because then you, the human, can perform the exact same task that the computer (via The Archive) does for you. It's nothing that a human with a computer cannot do. That's the ultimate independence of tools. That's our vision of (drumrolls) software agnosticism.
But someone using naming conventions based on TheArchive's implementation is not ending up with "agnostic" notes. They end up with notes that lose direct linking power in any other software, because TheArchive doesn't have direct links. Now, @sfast and @ctieze will say that it doesn't matter because such links can be implemented by manually searching for DTIDs. But I think this consequence (leaving TheArchive strips notes of their direct links) is not at all obvious, and some people would be quite unhappy to learn that they have to either recreate direct links or rely on a manual search strategy to reproduce them.
Tell me if I'm wrong, but I think that real software agnosticism would involve links that point to full filenames, either with a naming practice that prevents future filename changes or with software that automatically updates all links upon a filename change.
In closing, let me request that @sfast and @ctieze (and me and everyone else) keep in mind that we cannot just make broad claims about what is easy or hard to do in the ZK. Things like changing filenames, note titles (which might or might not be filenames, depending on software), and IDs are tied to software implementations in ways that are really easy to overlook. So we shouldn't be saying that it is easy or hard to change filenames - we should always be specifying the context of the claim (here, the assumed features of the software) when relevant.
Howdy, Stranger!
Categories
- 3K All Categories
- 152 Research & Reading
- 692 The Zettelkasten Method
- 7 Knowledge Work
- 99 Writing
- 464 Software & Gadgets
- 154 Workflows
- 729 The Archive
- 15 Plug-In Showcase
- 88 Resolved Issues
- 225 Projects Logs and Journals
- 83 Project: Zettelkasten.de
- 53 Critique my Zettel
- 171 Random
- 373 Introduce Yourselves!
Comments
I know of two other programs that implement [[wikilinks]] by searching for the double-bracketed text and returning the top hit: nvAlt and 1writer. I know that @Sascha and @ctietze have written about these two apps before - it may be that they've just overlooked this point since their ecosystems have supported this for such a long time.
I agree with the points that you make above regarding software agnosticism. For this reason, my notes are structured so that their filenames are their UID alone, with their title as metadata in the first line of the note:

This gives a number of benefits, with shortcomings that are relatively easily overcome. My direct links between notes are short wikilinks which do not disrupt the flow of text. My notes are written in markdown, making them easily exportable to a number of formats as-is using pandoc and a preprocessor which converts
[[UID]] to [UID](UID.md)(Many thanks to @mjknight who created this preprocessor). I can therefore export a number of notes in pdf or html format (or any number of other formats) with links between notes preserved.The only downside I can see to this system is when looking at note titles without any other context, for example in a file manager program or terminal list. Currently, my system of nvAlt on the mac, 1writer on iOS and iA writer on android mean that I never have need to look at a simple list of filenames. One exception to this is my index structure zettel, which is the common entry point into my zettelkasten. This has the UID of 000000000000 for easy searching and identification.
If I were to ever need to view my zettelkasten by filename alone, the design of the title metadata would make it relatively simple to write a script that appended the title in a machine-readable-format to the UID filename and convert it back once I'd finished viewing the filenames. Should I want to use the UID-title filename convention more longterm, another only slightly more complicated script could be written to alter the filenames in each directlink.
What's a full filename?
A full file path would be worse, because when links contain the path, you cannot even use your Zettelkasten from Windows and Linux/Mac. You'll have
C:\App Data\cobblepot\zettelkasten\amazing_note.txtvs/home/cobblepot/zettelkasten/amazing_note.txt, for example.If you just mean the regular fulename pat,")
amazing_note.txt, continue readingI don't see how any of this is "real software agnosticism":
amazing_note.txt, and never change it; or(2) is, well, not agnostic at all, it's exactly the opposite: you depend on software of that ilk.
(1) is a sensible convention; do try to write stuff that doesn't change.
(1) works best if the filename does not contain stuff that's prone to change, but something that can, by all means and purposes, be considered immutable data. If you never need to touch it, you will not run into trouble.
The creation date/DTID is one example. A GUID is another.
This guy here uses filenames that do not contain the note title, so files are called
0b9.md. (It's an increasing counter, which comes with different problems, but let's ignore these for now.)If you can live with something like
09b.txt, this might be the best, but also most hardcore, way to do it! I say use that, it's probably the truest of the real agnostic ways to stabilize file names.It also renders directory listings useless.
That's why I think the title is an essential component for usability's sake, but since it's mutable data, it's not to be depended on. It's nice for me, because I'm a stupid human who doesn't remember what
0b9was about, so I rely on telling filenames. This also makes the setup worse, because the filenames should change when I change the tile.Above, I said this is a good idea:
My litmus test for agnosticism is not to use the File Explorer, Dropbox, or whatever to browse an archive of notes; it's imagining a primitive teletyper. Nothing is clickable, and it only displays texts and directory listings. The filename will work in that scenario (provided you mark it as a link to your future self, reading the note.
[[...]]is an internet convention I stick to here, but anything works).If you omit the file extension,
.txtor.md, it works just as well. It's not the proper file name anymore, it's the file name without its extension, and still the convention works. In the same way, leaving out parts of the filename to its first 12 characters, that by convention contain e.g.202004241252, works just as well in that scenario -- because you, the human, can make sense of it. (And it's also a rule that can be taught to a computer, which is nice to make it do work for us.)Your litmus test seems to be how many apps support something natively. Partial file name lookup like the one I just outlines? Sheesh, I don't know, maybe none except the Notational Velocity stuff?
But full-text search for a phrase in a directory of files? That's supported by many more apps. (I do think more apps support full-text directory search than opening a file by its filename; so you'd be better off if you "encode" the file name in the note contents as well to get more coverage.) With that, you expand the range of suitable apps to virtually all text editors. It's a larger set than "apps that have clickable links to filenames", and larger than wikis, and text editors are available practically everywhere for everyone, while a web-based wiki requires knowledge about serving content on the web, and other apps require Java, which you may not even be allowed to use on your work computer, or whatever. Notepad++, Sublime Text, vim, emacs, Cortana/Spotlight full disk search, TextMate, BBEdit, VSCode, Atom, the list goes on.
Now if you litmus test really is how many apps support clickable links to files with lookup by filename, then you end up with far less applications.
I don't see how this is "real agnosticim" when that feature is so specialized already.
Author at Zettelkasten.de • https://christiantietze.de/
I assume their goal was to make the file contents (i.e. the Zettel) completely self sufficient, not requiring anything external.
It seems to me there is no real standard outside the use of URLs. Some expect it to match filenames, yet other titles. And what would the URL look like? You can't hard code the software's protocol if you want to have your Zettels remain software agnostic.
If you keep the software agnostics approach in mind for their arguments, I think their comments have been fair. About software agnostics, I liked this comment on another forum I saw a few days ago:
.
If your Zettels never leave your Zettelkasten, then it really does not matter much how you identify your Zettels as long as they can be identifier uniquely. However if you might link to your Zettelkasten from the outside, say a calendar application, then what ways of unique identifications you can use will get limited, assuming your Zettelkasten software cannot update the calendar application. That for me was the most compelling argument to use permanent UIDs, i.e. permalinks to my Zettels.
If you consider them permalinks then @Sascha is right, if not, and the software can fix them, then there is no problem at all, and I would agree with you.
This indeed seems rather specific on how the software handles linking.
Well I think it has objective value when thinking in terms of information available to use as the user. For the reasons explained in this comment.
You are wrong. Who says Zettels have to be files?
Who says Zettels have to be files? 
Seems a good thing to strive for. I do think you focus too much on software agnosticism being about working within as many software as possible, while I think its more about it exposing information usefully regardless of software used. Slight difference, but a key difference.
I do think you focus too much on software agnosticism being about working within as many software as possible, while I think its more about it exposing information usefully regardless of software used. Slight difference, but a key difference.
I can't speak for @Sascha and @ctietze so these were just my thoughts on the matter.
Let me just finish with my opinion on linking. I like to be able to use
[some text](<URL>)in my Zettels, so I will be using my own protocol for this, to make it possible to permalink and be flexible how software should handle them. I will probably still allow links like[[UID]], but convert them to[some text](<URL>)when saved to disk (and restored when loaded from disk).Thanks to the above commenters in this thread. I see I made a grave error in bringing up the phrase "software agnosticism" which was really not my intended focus. I was more focused on trying to highlight the difficulty of talking about typical practice in a ZK when users are implementing it with different software that searches and links differently. As I wrestle with trying to choose a software implementation (trying VS Code + extensions, now trying emacs + extensions) I am also realizing how much "working with" the ZK will differ in various software. E.g. Roam and Org-Roam distinguish themselves by presenting an updated list of backlinks whenever you have a note open. I don't think any other software does that. What are the implications of that difference in visual context? What about software that really does just search filenames or tags vs. full-text content?
@ctietze wrote:
It is interesting to see the contrast here with @Sascha 's comments about changing the "note title" part of filenames.
Now I am leaning towards unreadable numerical UIDs alone as filenames, with the idea that (as @mayebejames says) I can convert them later if I create titles as YAML front matter. But that kind of naming convention is hard to deal with without the right kind of software.
@ctietze wrote:
Might as well tell me the problems now before I adopt that guy's scheme, which I like much more than DTIDs for aesthetic reasons (i.e. indefensible reasons).
@grayen wrote:
Obviously they don't, but it does seem to be the easiest and most obvious way to practice the principle of atomism. And if we can eliminate any variables from the conversation (such as one-file-many-notes) it will help the discussion!
Getting back to linking, I think the most common way it's done (regardless of the actual syntax of brackets and such) is through reference to a full filename (not including path). TheArchive's reliance on search instead may be better because it is more accommodating of changes to other parts of the title, but it's not an option for me because I don't use a Mac.
Oh sorry, I wasn't careful enough when editing my answer:
I failed to add a "(But this is highly unlikely)". Setting the standard that high helps to not just slapping any old title onto a new note and be done, but giving it some thought. But you cannot strictly guarantee that change will never be necessary when the note title is used.
Now to the counter convention: as expressed elsewhere, a running tally requires contextual knowledge about the latest ID. You (a) need to look for the latest ID and increase it manually, or (b) depend on software to do the task for you. In the worst of all possible worst cases, where you don't have access to your")
WhatsTheLatestIDscript or whatever, note creation demands looking up the previously newest ID and then compute increase the counter. (At least that's all you have to do, as opposed to manually calculating a hash function in your head as was proposed somewhere else.) -- Date-based Ids only demand you learn to read the calendar and clockAuthor at Zettelkasten.de • https://christiantietze.de/
And yet it is trivial to implement. It was one of the first views I added to my personal VS Code extension.
It should even be somewhat easy to bring this to most code editors, just listen for file system events and see when a Zettel is opened, then update a backlink file and write down all backlinks to it, and if you have an editor that automatically recognizes changes to a file (most do), you can just have that backlinks file open in your code editor. Just a thought.
I mention some of the issues in my post about my choice of ID. I use IDs like
1goKig9, which still contain the timestamp + is short enough + is still sorted chronologically.At the moment I use the following translations on save and they restored on read:
[[Title]]->[Title](zettel://1goKig9)[marked text][#1goKig9]->[marked text](zettel://1goKig9)[#1goKig9]->[#1goKig9](zettel://1goKig9)I think that really depends on your particular tunnel vision (which we all have), i.e. the group of software you happened to have interacted with, which can differ wildly between people. I have looked at quite a few note taking applications and although using filenames is indeed common, its not like other ways are uncommon.
I think you could make this claim for embedding images, which I have only ever seen done by relative file path or URL. Although I plan to use Zettel IDs for them too, but I guess that is unconventional.
I think I speak for all of us when I say: We're gonna need to see this!!
Software agnosticism does not mean global compatibility or feature parity.
The unique ID principle means that you can find the note, regardless of what features your software supports. If your editor / tool supports plugins, you can create a more convenient experience to navigate between notes. If the tool doesn’t support modifications, that’s not zk’s fault.
VS Code and Emacs both have fuzzy file finders. So to follow a link, copy the ID and paste it into the FFF. That’s essentially what the archive does! I suspect that’s fairly simple to automate in either of those programs.
The unique ID principle means any developer can look at zk and say, “That’s cool, I want to support it.”
Haha, you truly love backlinks, don't you? They way I have implemented them for now is really nothing special, just a list of Zettels that link to the currently opened Zettel, and when you click, they are opened. I just started out my Zettelkasten and am still experimenting with the right way of writing. Once I have gained some more experience writing Zettels I plan to also show some context where the backlink occurred.
The inbound links on the screenshot are the backlinks:
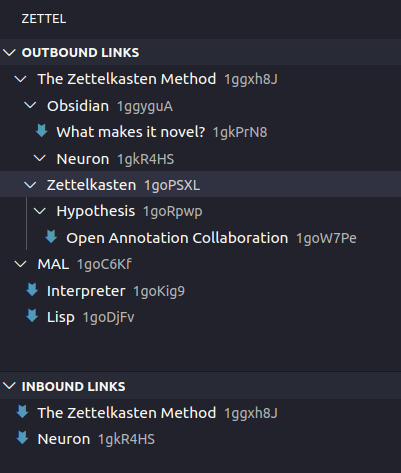
My current VS Code extension is just a place to experiment with Zettelkasten ideas for me, which is why I haven't published it. Once I have worked out some more details, I plan to write a dedicated application for it based on ProseMirror.
It truly was love at first sight. ☺️
Oh wow! That's awesome.
Can't wait to see it! Thanks for sharing your work. 🙏🙏🙏
@grayen:
I just want to chime in and say that I'm also interested in the code for making the forward/backlinks. They way you have them show up in the side panel looks great. I understand if you're not intersted in releasing it as an extension. However you'd help me a great deal by sharing a snippet. Day to day I use python not java/typescript so a starting point would be great.
@Eiff:
I've implemented backlinking without a real extension. It works ok. I like that I can control how much context I show. My biggest gripe is that links don't update automatically. Maybe this is helpful to you.
What I've done:
In my settings I've added the following command for reverse search
"command-runner.commands": { "reverse search": "rg ${fileBasename} -C2" }In my keybinding.json I've added a way to quickly access it
{ "key": "ctrl+alt+r", "command": "command-runner.run", "args": { "command": "reverse search" }, "when": "editorLangId == 'markdown'" },@ardee If it is still relevant to you, I finally had the time to address the issues I wanted to fix before publishing. Again, I am just aiming to have something workable until I finish my personal note taking app, so the extension is mostly just me experimenting a bit and for personal use, not designed for others.
https://github.com/msteen/zettel-vscode
Thanks a lot for sharing!
@mayebejames Would you mind sharing this pandoc pre-processor? I'm interested in doing something similar for the wikilinks & backlinks in my Zettel and having this script would be a great starting point for me.