An idle conversation around declaring PKM bankruptcy and starting over

Ever since I discovered the method and I glimpsed how valuable it could be to my use case (writing stories, which relies extremely on emergence), I have been tweaking, experimenting, trying software, finally landing on Obsidian for a long time, importing decades of notes into it, drowned, retreated to Bear in search of a lighter environment, finding myself looking for a more powerful environment again, getting drowned in Obsidian again, rinse and repeat.
I am now trying an experiment: declaring PKM bankruptcy. Begin an entirely new Obsidian vault, free from the years of "I want to learn that but never get around to" plugins (ahem Dataview), half-baked CSS snippets and various layers of sediment that has accrued and made the whole thing unwieldy. And then only add building blocks only if I commit to them and master them to make sure that I grow with the environment and methods.
My previous content, which has never been properly processed anyway, will become a giant inbox for the future. In the meantime, I'm still working in Bear, as I prepare – as a strictly hobby project – a proper future Obsidian vault, only adding back functionality that I find myself missing.
I'm sure people here found themselves starting their Zettelkasten / PKM again from scratch or wanting to. Did you? How did it work for you?
"A writer should write what he has to say and not speak it." - Ernest Hemingway
PKM: Bear, tasks: OmniFocus, production: Scrivener / Ableton Live.
Howdy, Stranger!
Comments
I just grew the new Zettelkasten over the older ones. Eventually, the inner notes shrivel, like everything else in life. I have different ID formats from other phases of the Zettelkasten. Suppose you believe a Zettelkasten is a second brain, which I don't. In that case, the inner notes are the primitive reptilian second-brain notes, the middle notes are the mammalian second-brain notes, and the outer notes--this analogy is absurd. The better analogy is that a Zettelkasten is a second drain.
Writing main notes stopped once I started using the daily and periodic notes plugins. There were too many daily notes, and I tended to copy unfinished tasks from one day to the next; I abandoned daily notes for weekly notes. But I still cannot get out of the weekly notes to write main notes, either. (UPDATE: I managed to extricate myself today.)
I still have yet to be surprised by anything in my Zettelkasten. Instead, I am disappointed, puzzled, embarrassed, and ashamed. I cannot say pleased. Relieved is the better word. I think of it as intellectual insurance. The question is, what is it going to cost me to write something down versus not writing something down? This question is almost right, but not entirely, because of hyperbolic discounting.
Since hyperbolically discounting the future is a human bias, the cost of writing something down now will outweigh an equal and opposite benefit in the future. If it costs me $(1)$ unit to write something down today, the benefit of recording it must be $(n)$ units $(n)$ days from now to be indifferent about writing it down.
Therefore, one cannot live "in the moment" when taking notes. (Unless you redefine living in the moment to mean considering the future in the present moment.) Living in the moment for me means hyperbolically discounting the future. However, you will need to discount the future exponentially when taking notes. If you guess you will need something six months from now, you're estimating close to the limit of human planning ability. Life is too chaotic to plan beyond six months.
You're playing a two-player game against a player who isn't present: your future self, at most six months from now. You estimate what a note will be worth to that future self and bury it in your Zettelkasten. I will waste fewer than half of my efforts if I am lucky. I should expect some wasted effort, but I want to keep this to less than half of my efforts.
If only I worked that way. I tend to work on what I feel like working on, hoping it will magically coincide with what I find helpful later, which almost works because interests tend to cycle.
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
@Zettelkasten I find the most value in creating zettels - from gathering, synthesizing, composing and pithily writing. That's what keeps me writing them. I need that series of exercises to sharpen my brain. There is still value in reading (and sometimes admiring) those zettels later as a refresher on the idea and reminder of the source material, and occasionally pulling a few together to write an article. But I see my Zettelkasten more as a quality (but incomplete) storehouse of information rather than a "second brain" (which infers some independent intelligence).
@KillerWhale If you have been careful and selective about what you include in your Zettelkasten, then I see no reason to dump anything or start over. Your ZK will grow slowly; some parts will expand over time, and some will languish. Some parts you will return to, and others you won't. C'est la vie. If you have collected a lot of junk that, in retrospect, should never have been allowed into your ZK, then starting over, culling, or letting them shrivel and die on the vine are all options
I occasionally revise zettels when I happen upon them (by whatever means), which is usually satisfying. I suppose you could try using a couple of tags - say a "last edited" tag (with a date) or a "quality" tag, which you could use to later track down old, poorly written zettels, with the intent of improving or discarding them. I use "#unfinished" and "#unlinked" tags to help me with ongoing maintenance. I put a bit more emphasis on the former and a bit less on the latter, striving to get a zettel to the condition where the "#unfinished" tag can be removed. That doesn't mean I'll never again revise it, but it shifts my focus away from that particular zettel and onto other things.
Something else that bears on your question needs to be mentioned. It is simply this: many people seem to be in a crazy pursuit of writing zettels, with an obsessive intent of somehow maximizing their ZK (whatever that means to them). It's akin to, but not the same as, those who are immersed in the "collector's fallacy". Like the sorcerer's apprentice, the more they can multiply their brooms (zettels), the more alive their ZK will become, and the more "intelligent" or "useful" it will be.
Now, I've set up a straw dog that should be refuted. The idea that a ZK becomes useful by some vague combination of mystical and magical multiplication is nonsense. It becomes useful by being created intentionally and for a purpose (the latter will likely change over time). As I mentioned to @Zettelkasten above, I don't see a ZK having independent intelligence. The value of your ZK depends on its content's quality and selectivity, as well as how effectively that content is linked and tagged. In other words, it must contain good information that your future self can find and build upon. And I don't believe the size of your ZK is all that important, although a critical mass is likely required.
I have no issue, by the way, with those who find joy in spending a lot of time in their ZK (the image of a digital garden comes to mind) or whose "crazy pursuit" is to meet the demands of a work or research project. My reference above is to those who are drawn into the Zettelkasten world without a clear idea of why or what they are trying to accomplish, and get bogged down doing the wrong things for the wrong reasons.
There was a discussion of this topic (restarting your ZK) about a year ago, buried in this forum thread, where @Will dropped a small bombshell:
https://forum.zettelkasten.de/discussion/2736/share-with-us-what-is-happening-in-your-zk-this-week-november-18-2023
(I found that reference by searching in my Zettelkasten, by the way)
The term "second brain" is preposterous. Incidentally, my username is @ZettelDistraction. Are you attributing intelligence to your Zettelkasten by addressing user @Zettelkasten?
It is a philosophical attitude that size is not all that important. I follow your practical advice on using tags like "#unfinished" and "#unlinked" to manage ongoing maintenance.
Some say that embarking on a career is transformative, meaning that comparing your present self with the person you will become is unknowable. If the Zettelkasten is as life-changing as some suggest, one's initial intentions or reasons for starting a Zettelkasten may be immaterial. As they go through the experience, assuming cultivating a Zettelkasten is transformative, they won't be able to judge whether they made the right decision at first. Only in retrospect can you say you are now a different person, having chosen.
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
Haha! Freudian slip of some kind.
Yes, that sounds reasonable. But so many get lost along the way to their journey's end (irrespective of whether they know the end)! I suspect for every person who has created a Zettelkasten that is transformative, 5 or 10 others are struggling in the weeds. Of course, my statistics are entirely made up.
@KillerWhale Since you open with not just a focus on Zettelkasten, but PKM in general, may I interest you in reading Oliver Burkeman's "4000 weeks" or "Meditation for Mortals"? This podcast episode got me interested in "treating todo's like a river to dip in" instead of backlog to process: https://www.artofmanliness.com/character/advice/time-management-for-mortals/ -- because you can never reach the end anyway. There's just too much life going on. (I found this almost trivial-sounding approach eye-opening in recent overwhelm.)
Sacha Chua recently picked this up on her blog, too, "Zettelkasten and Life with Kids":
https://sachachua.com/blog/2024/10/niklas-luhmann-s-zettelkasten-and-life-with-kids/
and "embracing the shallows":
https://sachachua.com/blog/2024/10/embracing-the-shallows/
→ declaring bankruptcy is not bad if you can manage to not fall into the "next time I'll finish everything" trap again")
My ZK contains stuff from 15 years ago that I can barely salvage, but these notes don't bother me. Notes that bubble up do bubble up for a reason. It's fine if some/most become mere sediment in this lake of possibilities. Wasted or untapped potential? Maybe, but I wouldn't know") Most importantly, the system should not be bogged down by this.
Most importantly, the system should not be bogged down by this.
Author at Zettelkasten.de • https://christiantietze.de/
@KillerWhale I have similar (yet slightly different) approach now: I do not call it "bankruptcy" as it is not important for me to focus on my debts ( = older or unprocessed notes). I try to build new, lighter, softly emerging, slowly built system (also in Obsidian, as well as you suggest).
But what I know from other areas (project management, time management implementation etc) is that the biggest danger for any new (growing) system is to overload it with data. So I put all my old PKM/ZK notes in other systems/places and will gradually build new Obsidian vault only with new information/articles/ideas which I will need at the moment.
As the new system will slowly emerge (I will do everything to avoid planning it at once and in the beginning, as this is the biggest trap IMO), I will/might gradually add some of my older notes etc. But I do not feel any pressure to add all of them etc. I will just build new system and I know that I have some backlogs of older notes elsewhere where I can go when I will be sure that my new system is tested enough to sustain bigger data load...
Thank you very much everyone – very interesting! @GeoEng51 , you hit the nail on the head.
AHEM.
I have been building as I go along, experimenting, tweaking, importing years and years of stuff thinking I would figure it out and –
Narrator's voice He did not figure it out.
I now have a mass of stuff, which is all imported in the same place, but which has very limited value because several generations of systems cohabit and they don't talk to each other. I see your point, @ZettelDistraction , but on my end these older generations bear little to no value because they drown the signal to noise ratio. I can work in there, but this is infuriating more often than not as I often myself with more than one note on one subject or project and of course there's different content on all of them. I could consolidate, but this speaks probably more to a problem of initial method and selection, and now I see where I've gone wrong.
To clarify, I'm totally fine with outdated content. It's just that I can't build anymore in there (or I can, but it's going to cave in and collapse on me in a few years).
@daneb Yes! I've been a little radical with the "bankruptcy" term, but this is was I've been doing – strictly as an experiment. I've started a new system where I'm just having fun writing, with good and simple methods from the get-go. I allow myself a few weeks to play on that, and if it works, I will gradually incorporate and cull things from the older places, as well as start nourishing it.
The important thing is, at the moment, this is just for fun. I hear you @ctietze – and Sascha mentioned this too – you have to be fine with the mess.
I find there is a very fine line between being fine with the sediment or older mess – a la @ZettelDistraction – and having the sediment still in a perpetual state of suspension, clouding the waters and making them undrinkable. This happens when they move too much, which is a surprisingly apt metaphor here 😆
Once must indeed remember that the system is not an end in itself, merely a means to an end, as our time is limited. But strangely, this thirst for a system that works does come from that fact. I am beyond irritated with myself that I have to re-learn some lessons in work and life several times. While every good Zettel's lesson in my system has stuck with me in ways they have not before. Time is short and I feel that I no longer have the luxury to be dumb.
"A writer should write what he has to say and not speak it." - Ernest Hemingway
PKM: Bear, tasks: OmniFocus, production: Scrivener / Ableton Live.
This is where we differ: I don't bother importing notes from antiquity verbatim. If anything I add to my Zettelkasten is based on something old, I rewrite or edit it.
The older entries differ because the ID or note format was different, but I have been updating them over time to conform to a format that works in Obsidian and Zettlr, though I no longer use Zettlr.
I have a couple of places where my projects end up in "Plans," "ToDo," and "Proj" notes, but one has to make a bureaucratic decision that there is one and only one place where you keep the "lab notebook," which you can set aside and then return as needed. There are electronic lab notebooks for this, though, now that I have made a bureaucratic decision, they are "Proj" notes; Bob Doto calls them CLOGs. Dividing work into projects and tasks makes sense if the non-project work items one records go into daily or weekly notes. I settled on weekly notes. This is a helpful system Bob Doto discusses in his book. You'll get the stagnant backup of wastewater you mention below without a system for managing the output.
This is why cats paw at the surface of their water bowls when they drink. Now, I don't write in my Zettelkasten: I write outside it and add what I want to keep in it.
I am reconciled to the profligate waste in biology. It's a safe bet that much of what I have accumulated is junk to be discarded. I don't add my older notes verbatim to my Zettelkasten and often start new notes. I don't see a way around learning and relearning a subject. I make a virtue of necessity and rewrite notes before they go into my Zettelkasten. Abandon the pristine, all ye notes who enter here.
You do want to settle on a standardized note format earlier rather than later so it doesn't become a burden to change formats; this is what I meant by older systems. I did not mean that I stored old notes from years ago that predated my Zettelkasten in my Zettelkasten. Most of those older notes no longer make sense; they were wrong, or I have gone beyond them.
I have had to "rescale" my interests more than once. I no longer play the piano or compose music. I decided I was too old to be a prodigy. I have been drawing less. I still program and work on mathematics; the projects can go on for months or years. I started writing doggerel again (I must have been doing this intermittently for at least a quarter of a century).
If something is merely interesting, such as amateur radio or a new finding on cat intelligence, I will read about it but not take notes. (I will take notes on cultural transmission in orcas—don't beach yourself!) This is contrary to Ahrens' gospel, which is to read with pen and paper in hand and make writing the only thing that counts. I follow Ahrens' imperative to live life to maximize writing opportunities, but I am not a fanatic; otherwise, I would never read the Zero Retries amateur radio newsletter since I rarely take notes on anything I read there.
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
@ZettelDistraction Thank you very much. You have very aptly described my huge mistake: thinking the system could absorb the inbox of decades without having properly put some guardrails into place, that is, methods – figuring out exactly how I'm going to do things.
This takes some practice, I find. You need two things:
It's easy to think of all the awesome things you can do with a tool, it's much harder to understand exactly what you need for the system to be, indeed, living instead of ending up as a bureaucratic nightmare. I will mention in passing that Obsidian is a terrible trap for this: thousands of plugins, endless CSS customisation possibilities, and a million YouTube gurus with arcane Dataview requests and the promise that your life can achieve a zen-like state of pristine condition. Which it does not, and should not – for sure. But it's hard not thinking "oh, that's cool! I'm just going to install this and not activate it, I'll get back to it later, that can't hurt" –
It does. Half of whatever I installed in my original vault I no longer have any idea why.
You need to understand how you work, and by that I mean: how you function. In my case, I need something that requires the absolute least maintenance while still allowing for immediate writing, finding stuff later, and a few weird edge cases such as geolocation for some notes and heavy media support. And there are absolutely things I will never capture. Incubation in the unconscious has its place – fun and light reading with not ulterior motive whatsoever too!
I look back on my Evernote days fondly. I had a perfect system for me at the time: I could capture to my heart's content with a personal well designed system of tags, and that would ensure I would write AND file on the fly and never revisit things. I had no inbox. Of course, taste and needs evolve, and now EN has fan from grace with once stellar features (the web clipper) having not caught up to modern standards.
This experiment of a new, fresh vault into which I carefully, very slowly reintegrate content, tweaks and plugins on a per-needed basis (as you are describing) has made me more excited about my system than I've been in a long time. Now I need to write my methods and protocols down, and if all goes as hoped, they will be a single Zettel as they will be simple and approach the "write and put it where it belongs in the same move" issue I've long been having.
Thanks for paying attention to my little case. 🙂
"A writer should write what he has to say and not speak it." - Ernest Hemingway
PKM: Bear, tasks: OmniFocus, production: Scrivener / Ableton Live.
I have one plugin like this--I think it was because another plugin required it.
The paradox of Zettelkasting and PKM (and perhaps in all significant life changes) is this:
This connects to L.A. Paul's work on transformative experience - just as you can't know what it's like to become a parent until you are one, you can't fully understand how a Zettelkasten might change your thinking until you've developed one. So what do you do? Start with simple guidelines such as those I eventually hit on, and let the system evolve with you. (Or else try commonplace books as @chrisaldrich suggests--there are time-tested alternatives.)
Here are the guidelines I follow now. Some don't apply to fiction writing, but since I began writing doggerel again (and posting before revising), they are generally helpful.
Guidelines for Maintaining a Digital Zettelkasten
Edit Old Notes Before Importing Them
Choose and Stick with a Consistent Note Format
Organize Projects and Tasks
Write Outside Your Zettelkasten
Ahrens writes, "... there is no reason not to work as if nothing else counts than writing" [@ahrensHowTakeSmart2022, pp. 34-35].
Ahrens' maxim has some consequences:
Rewrite and add notes as your understanding changes
Efficient Reference Management with Zotero and Better BibTex
Physical Setup Considerations
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
@KillerWhale, I should say something about my physical setup to clarify why I write outside the Zettelkasten first (usually) and then create notes using what I've written.
The Zettelkasten app appears on a smaller secondary monitor I can refer to as I work. If I need to track my work, I often have the monitor open to this week's weekly note.
CAUTION: Recording tasks in periodic notes can keep you from doing anything else in your Zettelkasten, which is another reason to write outside the Zettekasten and then add to it.
The smaller secondary window constrains my working environment, encouraging concision. Finally, copying what you've written to the secondary Zettelkasten monitor takes effort, which prevents any tendency to add everything in sight.
I will think about adding this to my guidelines.
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
@ZettelDistraction That is hugely useful, thank you. Many of those principles I have definitely failed to follow.
"A writer should write what he has to say and not speak it." - Ernest Hemingway
PKM: Bear, tasks: OmniFocus, production: Scrivener / Ableton Live.
@KillerWhale
What i suggest to you is throw all your old notes into one folder, then install Smart Connections plugin, embed them for similarity and semantic search.
As for dataview - even perplexity can write any query for you now.
You can watch just read systems thinking and watch August Bradley's PPV for ideas on systems. After that you will see that all those gurus are repeating same things but making it overcomplicated and less effective.
PKM bankruptcy - found myself there several times. Using logseq currently. Sometimes open logseq vault in obsidian for smart connections plugin.
Also i use object-based approach. Since logseq is an outliner, it is easier to manage small items compared to obsidian.
Maybe i would use Tana.inc if it was not online only and that expensive.
Trying to find best tool is real pain (it may be even small project only 5 people know of). I often see people give advice "just use one tool", but i think it's very empty generic advice. There IS better tools, better methods. Look at Infranodus.
Simultaneously, there's utter crap tools and systems. Even worse - people recommend them, but upon closer look those apps are just useless crap with some font and icons changes. And it becomes more and more difficult to tell what is what.
Overloaded obsidian vaults goes here too - people install plugins just to have them, half of their plugins likely will be outdated in couple of years, they just add clutter, yet it is called "future proof".
Part of that problem might be that people just very unskilled in knowledge work/management => overvalue their opinion, but that's another topic.
Yet i am still trying to find better systems and tools. Especially those which will reduce manual computing to minimum. And allowing to sail the endless chaos/streams of information. One such example - famous collector fallacy can be almost completely ignored with Incremental Reading and RAG.
Simultaneously i feel doomed having to dig through all tools, systems, opinions, proofs of concepts.
Even harder to find one which allows integrations and automations out of the box such as Notion.
Even harder to find something that allows such seamless and fast collaborative knowledge work.
I'm using logseq as well. I downloaded Obsidian to see if it can open my logseq files, but haven't tried it yet. Any tips? Can Obsidian open logseq's files directly or do you have to change something?
@GeoEng51 they can work together, the only thing is to remember to write properties in logseq format, obsidian can view them as inline properties with dataview plugin
I had trouble with logseq/Zettlr/Obsidian compatibility. If you use logseq, you must reconcile yourself to its outline-focused subset of markdown. Here are my findings (also see https://forum.zettelkasten.de/discussion/comment/21566/#Comment_21566).
It's not worth trading off YAML variables, which work with many markdown editors and viewers, in favor of logseq properties. An example markdown file below illustrates logseq's constraints on YAML and markdown.
--- id: FALSE202411201202 title: FALSE202411201202 Logseq markdown peculiarities reference-section-title: References --- id:: FALSE202411201202 title:: FALSE202411201202 Logseq markdown peculiarities reference-section-title:: References - # Logseq markdown peculiarities In logseq markdown, h1, h2, h3, h4, h5, and h6 subsection headers must come after a dash. Zettlr doesn't render this correctly, though PanWriter does. logseq renders a subset of markdown in which the list is the basic structure. Also, SHIFT-ENTER must be used within logseq to keep the text within the section, though this is true w - ## Zettlr cannot handle logseq markdown Nevertheless, logseq properties aren't compatible with Obsidian, PanDoc, or Zettlr. logseq does not recognize the enclosing triple-dash standard for YAML headers. logseq also identifies the title with the filename of the markdown file instead of using the id. - ## SEE ALSO - [[FALSE.0.23.1214]] False assertion - [[OBSID202410130931]] From Zettlr to ObsidianGitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
Thanks for the suggestions @Ydkd , but this is one of several places where I studiously avoid LLMs, even running locally. I strongly believe in the strength of connections I make myself, in the process of making the notes themselves – I have seen that this is where the insights come from; not in the result, but in the doing ("Writing the medium of thinking", as Ahrens says).
I wholeheartedly agree that there are better tools, though, and that "just using what you have" is not entirely realistic. What does not exist, however, is the ideal tool and that quest has to be put to rest at some point. Ideally, we should use simple to grasp, hard to master tools, with a huge range of progression that can open with well-though features and/or extensibility (Bear, Obsidian, The Archive).
I'm happy to hear I’m not alone in the reboot boat! (The reboat?)
All this conversation has really spurred me into putting more serious thought into my "bonsai garden" (this new vault I'm trying to establish sound principles around). So far, I'm loving it, so much that I must resist the temptation of switching entirely to it – that would be replaying the same mistakes.
"A writer should write what he has to say and not speak it." - Ernest Hemingway
PKM: Bear, tasks: OmniFocus, production: Scrivener / Ableton Live.
@ZettelDistraction
There's no logseq markdown. Logseq is an outliner. Everything is simultaneously a block and text => must be in outline, which can be infinite.
idproperty is reserved property in logseq, every block can have an id. Read about this here if you interested - built-in properties. If you set id by yourself, you will break things.Feels like you just don't get that kind of philosophy.
yaml can be converted by simple script. Furthermore, yaml is not part of markdown.
Logseq can work with yaml, you just have to follow this structure:
@KillerWhale
i'm not telling you to ask llm to think for you, i'm telling you to use semantic search, rag etc. It's not copypasting your notes to llm, maybe you havent heard of it, idk.
One of the reasons that large amount of notes becomes unusable is retrieval/search becomes nearly impossible. You can't find quickly notes which are semantically close to certain note or to your query (intent/idea) without knowing exact tags,keywords etc.
Manual search is monkey work, it doesnt help with thinking, you dont get anything out of it - it's like using big paper dictionary instead of online translator.
"AI" does this job way better. It even helps with serendipity better.
To address your points:
Text Must Be Nested Under List Items: In Logseq, all text must be nested under list items (
-), or it won't render correctly. This requirement creates a subset of Markdown that I've referred to as "Logseq markdown." Logseq's subset assumes that notes are outlines. Not everyone writes this way, and the requirement conflicts with editors that expect headers and paragraphs at the root level.Handling of Filenames and Titles: Logseq ties the page title to the filename, ignoring any
titleproperties in the YAML front matter or elsewhere in the document. Editors like Obsidian or Zettlr allow you to set a custom title in the metadata regardless of the filename. Logseq's filename limitation affects how notes are organized and displayed.Reserved
idProperty: I'm aware that Logseq reserves theidproperty and that manually setting it can cause problems. However, in other tools, using anidin the YAML front matter is typical for metadata management. That setting anidmanually "breaks things" in Logseq is one of the interoperability issues I'm pointing out.No YAML Support in Logseq: Logseq doesn't recognize the YAML front matter and will ignore any metadata you include using YAML syntax. This lack of support is a significant compatibility issue when using Logseq alongside other tools that rely on YAML for metadata, like Obsidian, Pandoc, or Zettlr. Incompatibility with Pandoc is a non-starter. I rely on Pandoc, which works with YAML to include LaTeX packages and macros in documents. Logseq has a Pandoc plugin, but I would still need to rewrite notes containing YAML variables passed to Pandoc to view them in Logseq, which would change them into outlines. This is to say nothing of working around any issues a new plugin with new software introduces.
Logseq Requires Properties: Instead of YAML, Logseq uses its property format, which involves placing
property:: valuedirectly in the content. This format is incompatible with standard Markdown practices; other editors do not recognize properties.Incorrect Claim About YAML Structure: You claim I can make YAML work in Logseq if you follow a specific structure:
Even if you format your YAML this way, Logseq won't process it as metadata. The content must still be nested under a list item (
-), which deviates from standard Markdown and doesn't resolve the YAML incompatibility.Interoperability Issues Remain: Because Logseq doesn't support YAML, any metadata you include for use in other tools won't be available in Logseq, and vice versa. While you mention that YAML isn't part of Markdown, it's become widely accepted for including metadata in Markdown files, supported by many editors, document processing tools such as Pandoc, and static site generators.
Conversion Scripts Are Workarounds: Suggesting simple scripts to convert between logseq properties and YAML variables misses the point of interoperability. The goal is to have files that work with different tools without extra steps or conversions.
I understand Logseq's philosophy, which complicates working with other tools because Logseq insists on a proper subset of Markdown and does not recognize the YAML standard. I will illustrate this with two examples, the first showing that this web site cannot render an H2 header in a list item.
Example two
This is a markdown file
--- id:: Well202410051325 title:: Well202410051325 well well well reference-section-title:: References --- - ## well well well We cannot start with a single h1 header without Markdown Lint complaining. We must start at h2. - ## SEE ALSO To use logseq markdown h1, h2, h3, h4, h5, and h6 subsection headers must come after a dash. Zettlr doesn't render this correctly, though PanWriter does. logseq renders a subset of markdown in which the list is the basic structure. Also, SHIFT-ENTER must be used within logseq to keep the text within the section. - ### Maybe Zettlr cannot handle logseq markdown Nevertheless, Logseq properties aren't compatible with Zettlr or PanDoc. logseq does not recognize the enclosing triple-dash standard for YAML headers. logseq also identifies the title with the markdown file's filename. - ## ReferencesIssues Identified:
YAML Front Matter with Logseq Properties:
id:: value). However, Logseq does not support standard YAML front matter enclosed within triple dashes (---). Instead, it expects properties to be defined within the content using its syntax.id,title, andreference-section-titleare not processed by Logseq, leading to inconsistencies.Nesting Under List Items:
-). This is evident in the example, where headers like## well well welland## SEE ALSOare prefixed with a dash.Headers Within List Items:
##,###) inside list items (-) is unconventional in standard Markdown. While Logseq can handle this due to its outliner nature, other Markdown editors may not, leading to skipped content or rendering errors.- ## well well welwas skipped, and Logseq even caused a crash. This suggests that Logseq struggles to parse or render this non-standard structure correctly, leading to data corruption or instability.Title Handling:
titleproperty within the document. This means that setting a custom title within the YAML front matter (which Logseq ignores) has no effect, leading to potential mismatches between desired titles and actual filenames.Impact on Workflow:
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
@ZettelDistraction
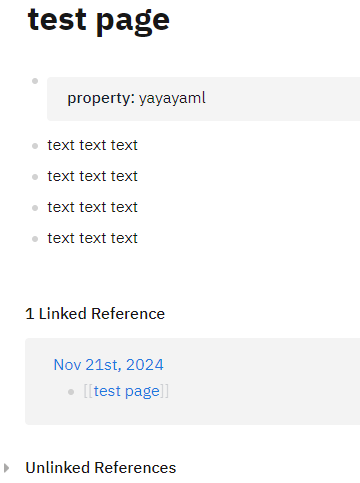

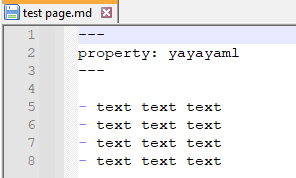
Logseq perfectly understands YAML:
"Not everyone writes this way" - very simple version of markdown is standartized, but there's a lot of variations. It's still a markdown list at its core. Not every markdown editor understands YAML too. If you want to write long-form - just ignore bullets.
Inability to change built-in property names is indeed a problem.
"The goal is to have files that work with different tools" - do you really want to lose functionality just for the sake of traditional markdown? Obsidian exists already.
There's also orgmode which is also widespread standard.
"which complicates working with other tools", "workarounds" - It's not peculiartities. It's functions, they allow to do more work in one tool instead of several tools. With basic markdown editors you also need to script your workarounds. And why do you need to use several markdown editors?
@ZettelDistraction
You are also wrong about h1 headers:
--- test-id: Well202410051325 test-title: Well202410051325 well well well reference-section-title: References --- - # well well well We cannot start with a single h1 header without Markdown Lint complaining. We must start at h2. - ## SEE ALSO To use logseq markdown h1, h2, h3, h4, h5, and h6 subsection headers must come after a dash. Zettlr doesn't render this correctly, though PanWriter does. logseq renders a subset of markdown in which the list is the basic structure. Also, SHIFT-ENTER must be used within logseq to keep the text within the section. - ### Maybe Zettlr cannot handle logseq markdown Nevertheless, Logseq properties aren't compatible with Zettlr or PanDoc. logseq does not recognize the enclosing triple-dash standard for YAML headers. logseq also identifies the title with the markdown file's filename. - ## References--- test-id: Well202410051325 test-title: Well202410051325 well well well reference-section-title: References id:: 673ec9e4-16ef-4abf-8b93-742e859a956a --- - # well well well - We cannot start with a single h1 header without Markdown Lint complaining. We must start at h2. - blablaba #idea - idea1 type:: idea - ## SEE ALSO - To use logseq markdown h1, h2, h3, h4, h5, and h6 subsection headers must come after a dash. Zettlr doesn't render this correctly, though PanWriter does. logseq renders a subset of markdown in which the list is the basic structure. Also, SHIFT-ENTER must be used within logseq to keep the text within the section. - idea2 type:: idea - ### Maybe Zettlr cannot handle logseq markdown - bkoopsdkfposdk #idea - Nevertheless, Logseq properties aren't compatible with Zettlr or PanDoc. logseq does not recognize the enclosing triple-dash standard for YAML headers. logseq also identifies the title with the markdown file's filename. - idea3 type:: idea - ## References - ## Ideas in this page - {{query (and (or [[idea]] (property :type "idea")) (page <% current page %>))}} query-table:: true query-properties:: [:block :type]When you start manipulating page in some way, logseq assigns an ID to it, same happens when blocks are referenced manually
I’m aware that Obsidian exists—I use it. The point of this discussion I referred to was to evaluate Logseq as a potential alternative to Zettlr. Given my reliance on Pandoc, LaTeX, and YAML front matter, I needed a tool that could handle these without requiring changes to my existing notes and configurations. Logseq’s incompatibilities with standard Markdown, its lack of YAML support, and its outliner-focused subset of Markdown made it unsuitable for my workflow. Obsidian ultimately met my needs better, but that doesn’t mean the limitations of Logseq shouldn’t be addressed for users in similar situations.
Irrelevant.
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
You misunderstandi my point. That is not an H1 header at the root level—it is an H1 header within a list item. This distinction is exactly what I am criticizing: Logseq requires all content, including headers, to be nested under list items. This deviates from standard Markdown practices, where headers can exist at the root level.
Your own example reinforces my argument. In standard Markdown, # well well well would be rendered as a top-level H1 header, but Logseq forces it to be nested under -, fundamentally altering its structure. This constraint creates a subset of Markdown that I referred to as 'Logseq Markdown,' which is incompatible with tools that expect standard Markdown.
Please read my original critique more carefully. The issue isn’t about whether Logseq renders H1 headers inside list items; it’s that this structure deviates from Markdown standards and causes problems when working with other tools.
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
@ZettelDistraction
my main point is such critique don't really apply to logseq due to outliner design and extended functionality, but would apply if logseq was basic markdown tool, but adjustments for yaml and built-in properties should be there indeed
Thank you for your response, but your main point misunderstands the context of my critique. This discussion is about ‘declaring Zettelkasten bankruptcy and starting over.’ Contrary to your claim, my critique of Logseq absolutely applies. Evaluating Logseq as a Markdown tool involves assessing its compatibility with established standards and workflows.
I evaluated Logseq and Obsidian as alternatives to Zettlr. I use YAML in notes to pass variables for Pandoc, YAML in “defaults files” for Pandoc exports, and a LaTeX template for Pandoc which uses YAML variables defined in several of my notes. Logseq’s outliner design doesn’t exempt it from handling YAML or adhering to Markdown standards when evaluated as a Markdown-based tool.
You acknowledge the need to convert YAML to Logseq properties and conversely, and to avoid reserved property names. For workflows like mine, which depend on YAML metadata and interoperable Markdown files, Logseq’s current handling of metadata and Markdown are incompatible. The so-called extended functionality (whatever that is) comes at the cost of interrupting established tools and workflows, creating unnecessary friction.
VS Code’s Markdown Lint plugin flags issues with ‘Logseq markdown.’ This reinforces my critique: Logseq’s subset of Markdown deviates from standards, creating unnecessary problems for users who rely on multiple tools that expect consistent Markdown files.
Let’s take the Markdown example, change it to reduce the number of Markdown Lint errors, and set aside for the moment that Logseq does not recognize the YAML header:
--- test-id: Well202410051325 test-title: Well202410051325 well, well, well reference-section-title: References --- - # well, well, well We cannot start with a single h1 header without Markdown Lint complaining. We must start at h2. - ## SEE ALSO To use Logseq markdown h1, h2, h3, h4, h5, and h6 subsection, headers must come after a dash. Zettlr doesn’t render this correctly, though PanWriter does. Logseq renders a subset of markdown in which the list is the basic structure. Also, Logseq requires SHIFT-ENTER to keep the text within the section. - ### Zettlr cannot handle Logseq markdown Logseq properties aren’t compatible with Zettlr or Pandoc; it does not recognize the enclosing triple-dash standard for YAML headers; and it identifies the title with the markdown file’s filename. - ## ReferencesNow we are down to one markdown lint error:
MD041/first-line-heading/first-line-h1: First line in a file should be a top-level heading.This applies to the line beginning with- #.I don’t have the time to pursue this further.
GitHub. Erdős #2. Problems worthy of attack / prove their worth by hitting back. -- Piet Hein. Alter ego: Erel Dogg (not the first). CC BY-SA 4.0.
@KillerWhale
Also regarding saving your old notes - you can run AI through them (4o is cheap and fast, but you can run local model for following tasks successfulyl).
You just generate small list of tags for each note, and you can specify tags which were related to your workflow. You can put them in yaml "suggested-tags" property or smth.
After that you get tagged notes and list of tags. From here you can either by yourself or using nlp/llm merge tags into more general tags and rename.
After that you can again ask llm to give summaries of content under each tag and then decide which to delete and which to retain.
Or you could use clustering or try smth like Infranodus
@Ydkd Thanks, this is probably a great use case for AI, but I have to admit that I profoundly detest those things at the moment, their clunkiness (Smart Connections never worked properly on my end and, when it did, never told me things I didn't know; I still do things faster than the time it takes me to prompt them to do them for me), what they represent and how they were built. I'll probably come round at some point, but the moment has not yet come. 🙂 Manual work will be where it's at for this project.
"A writer should write what he has to say and not speak it." - Ernest Hemingway
PKM: Bear, tasks: OmniFocus, production: Scrivener / Ableton Live.
@KillerWhale
Smart Connections's result will vary depending on embedding model and LLM model (if you use chat). But i don't talk here about chat, just clustering, classification, tagging, which have to be done outside of smart connections and obsidian as it can't process notes iteratevily. If you developed some new note format, LLM can reformat all old notes, it is possible to prompt it not to remove any words and just change format
But im assuming here you have hundreds of old notes
@Ydkd For this, reformatting stuff, I would trust it and it would indeed be a major timesaver. Smart Connections was probably very meh as I only used local models. But there's no way in hell I'm using ChatGPT on any online monstrosity on my Zettelkasten. I will do without, and happily die on that hill.
"A writer should write what he has to say and not speak it." - Ernest Hemingway
PKM: Bear, tasks: OmniFocus, production: Scrivener / Ableton Live.