Exposing the zettelkasten to the quantitative eye

As an interesting and fun learning project, I've written my first python script. And I love to share it with you. I've exposed The Archive to explorations of the quantitative eye. You can look into mine and look into your own archive.
If you are a coder, I know you have many other things on your busy schedules, but I'm asking if you'd take a couple of minutes to look at my coding attempt and offer whatever help you want. Even just pointing me where or what to look for would be a great help.
Dependencies
python 3pip3 install pandaspip3 install ploty
The phyton script calls a shell script. I want to combine the shell script into the python script but learning about converting actions is slow. Install these together in a test directory and set the "user variables" in both scripts to what is appropriate for your system. Then all that needs to run from the cmd line is python3 graph1.py. This will NOT modify your archive in any way.
It plots graphs for your zettelkasten's word count, link count, and the number of zettel. It doesn't require Keyboard Maestro, Alfred, Hazel, or crontab/launchd. It does this all in one go. I think the value is you wouldn't look at these stats on a regular schedule. This script should run faster than it currently does. Do you have any tips for running this faster?
Please don't laugh too loudly at the code. At least not so loud as I can hear. I'm sensitive. I'm a beginner. But helpful, constructive criticism is welcome.
Description
There are two scripts. statshistory.sh
- a shell script that collects the data from the zettelkasten
- needs to be set executable with
chmod +x statshistory.sh - it has problems in that it increments past the end of each month, 30 to 99, and depending on the size of your zettelkasten, multiple years of months this takes a lot of time where no data is collected
- the time values running this script on 2278 zettel is
time sh statshistory.sh real 9m12.950s user 3m34.750s sys 6m6.445s
- a smaller subset of one's archive could be graphed to focus time
graph1.py
- my first python script that produces simple graphs (see below)
- requires
pip install plotlyandpip install panda - I'd like to find a way to prompt the user for variables (the zettelkasten location, beginning UUID, and ending UUID)
- calls the shell script
- reads temp.csv
- each line represents a day
- ploty is a very cool plugin and available in many environments
Assets
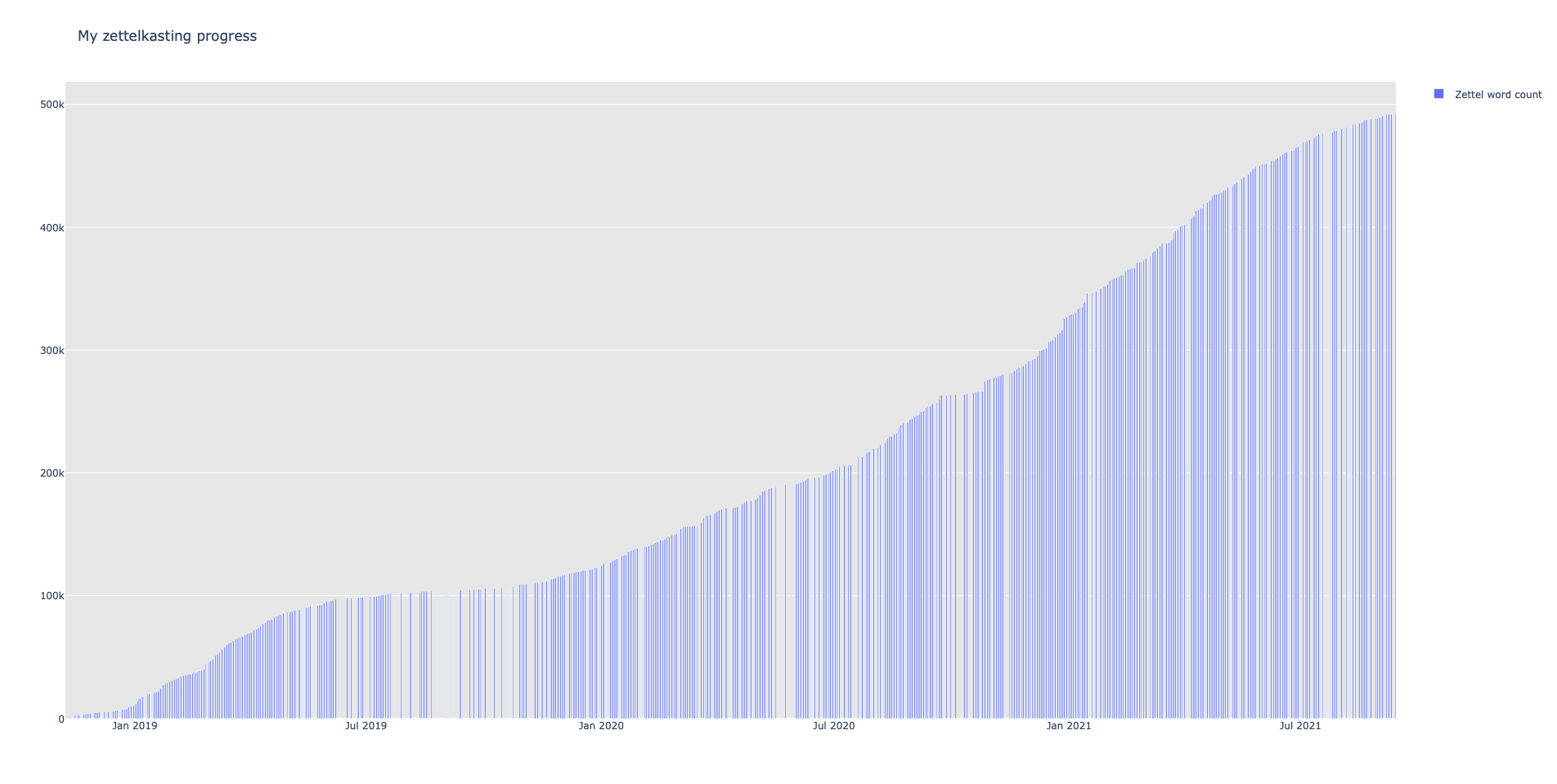
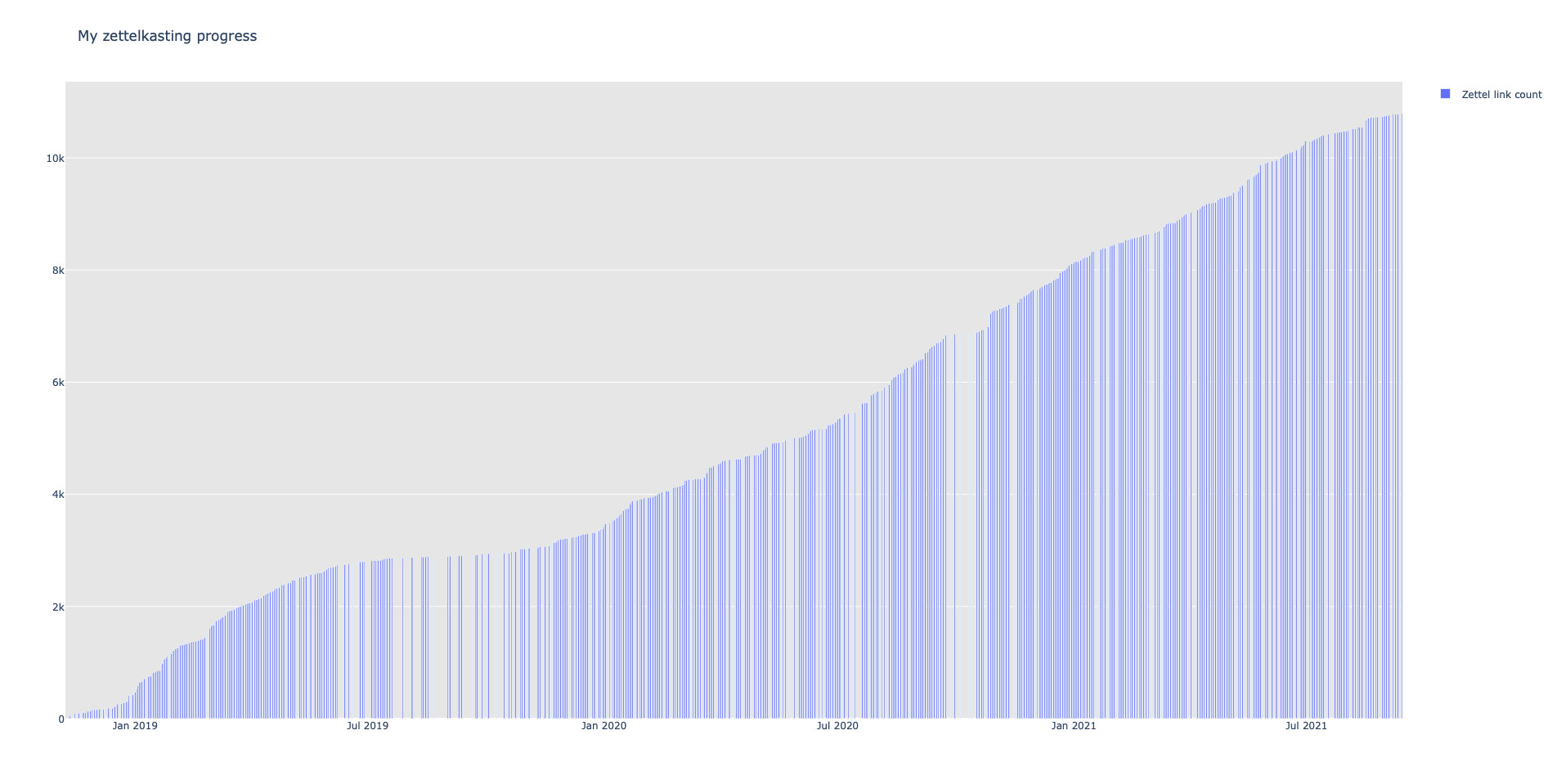
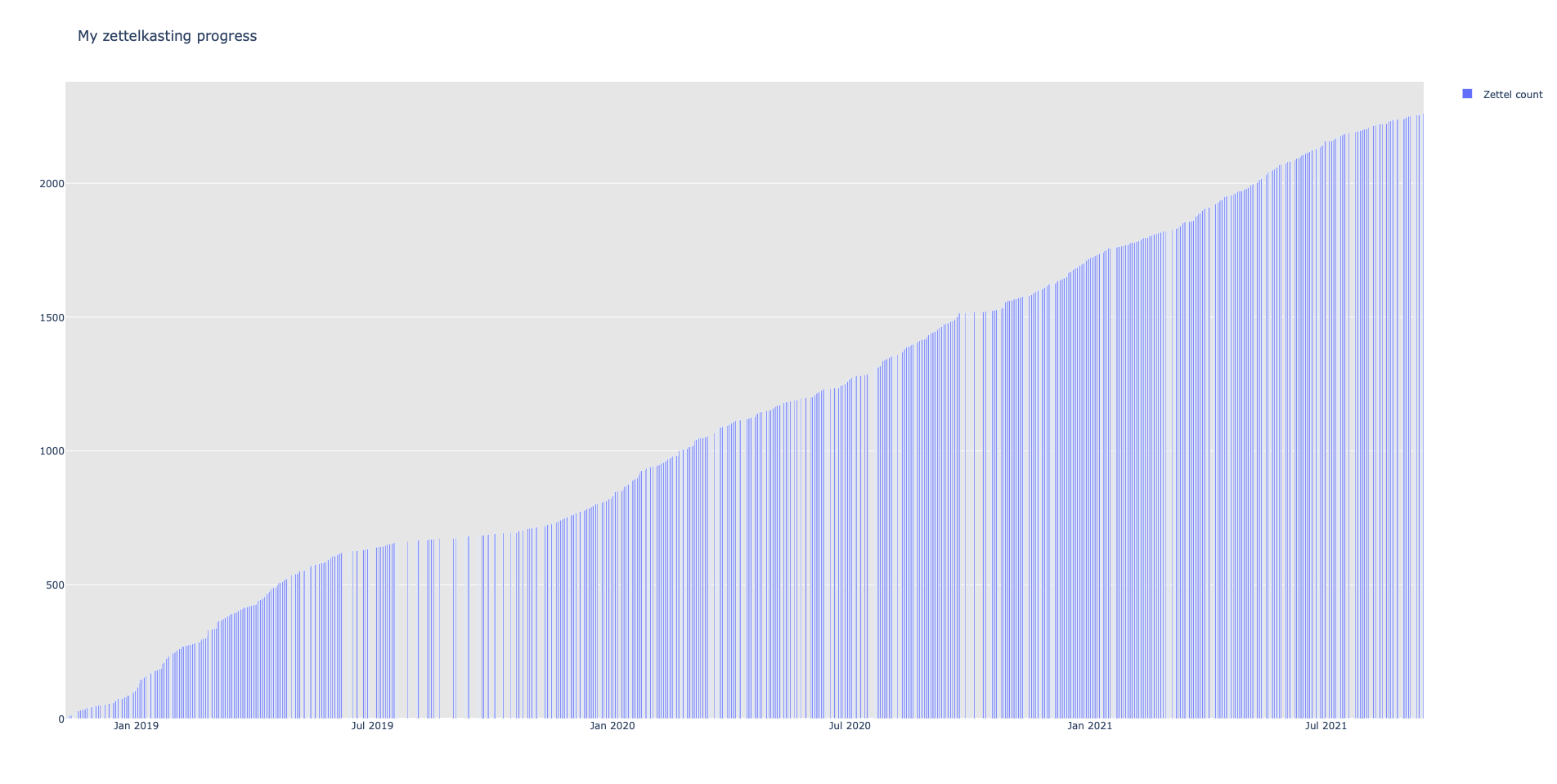
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Howdy, Stranger!
Comments
Very cool! I've been enjoying your keyboard maestro stat readout over the last couple weeks. This makes a very nice addition to that!
I don't have much experience in Python, so any advice I offer is highly speculative. Those runtimes do look long, though. My initial thought is to parallelize this. The order that you analyze each note doesn't matter since the date in written out in the title of the note, so you can analyze multiple notes simultaneously. I don't know if this is a simple recommendation in Python, though. My second thought is that if you can read the system's "Date Modified" of each file using Python, you can add this date to your statistics csv. Your code can check this date and only update the statistics on files that have a modified date different from the last time you ran the code. That may cut down the runtime after the first run.
There's probably a simpler way to optimize this outside of my recommendations. Coding is not a central feature of my job, so when I do code it's usually held together with duct tape and a prayer. I might take a spin at doing some ZK data analysis for myself. It would make for a fun learning experience, either for Python or for expanding my knowledge of the language I do use for work.
ORCID: 0000-0003-2213-2533
My personal suggestion is to not do parallelization because that makes everything more complicated") Thing is that the
Thing is that the
.shscript eats the time, not the Python script.There's a couple of possible bottlenecks in the shell script:
+1increment produces a lot of wasted timefinditself isn't fast: for a totally empty directory, Will's original date range of 20181101--20210913 in the script takes 2:30 minutes. With a data range where no file is found (1919--1921) but in a folder with files, i.e. in my ZK folder of ~6300 files, 15 iterations take about 1 second. Without actually finding a file. With 44000 files in a directory, each 5 iterations take 1 second. The more files, the slower find becomes.egrepshouldn't matter if no file is found, so that's not a huge bottleneck)31up to99(and00), as @Will mentioned, produces 2/3 wasted loop iterations per regular month of each year13to99(and00), which could also be skipped -- and each of these non-existing months have 100 iterations for the day part of the timestamp (for these months, the whole range of00to99won't exist)12*69wasted iterations per regular month +88*100wasted iterations for fantasy months, making more than 9600 wasted iterations total per calendar year. At a rate of 20 iterations per second, that alone might take 8 minutes in my real ZK folder: 9600 wasted iterations compared to less than12*31=372useful iterations in a calendar year means that the ratio of useful-to-wasted iterations is ~1:25 -- so 25x is roughly the speed improvement you can expect when you add a date increment function that does a bit of logic checking first, wrapping e.g. 2020-11-31 to 2020-12-01. Doesn't even have to be smart about February, leap years, which month has 30 vs 31 days, etc.findlooks for all files with the*$sdate*.mdpattern, and thenegrepdoes it as well again. The drive becomes the bottleneck eventually.Another improvement might come from writing everything in 1 Python script. Then you can glob for all files in the ZK directory, sort the resulting file names, split by year/month/date pattern, maybe ignore all that don't match or use their creation date, and finally loop over the filtered and sorted file names to extract both the word count and the link count at the same time from the file -- this means each file has to be read from disk only once, which might help.
Hope these suggestions help make the script faster!
Author at Zettelkasten.de • https://christiantietze.de/
Thank you both for taking the time to look at my efforts.
Yes, if I run the Python script on the CSV previously collected, the Python script runs in a second or two real-time.
I think this is the root of the wasted time. As you so eloquently explain, not accounting for the limited days in a month and months in a year causes
findto spin empty cycles and suck time.What might be faster?
I've started rewriting the Python script to incorporate the shell script, but as a beginner in Python, learning the new syntax and framework is coming slowly. I'll have to investigate how Python might increment through dates. Or maybe I need to shift my thinking.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Regarding learning Python: the biggest bang for your buck (time investment) would come from finding and reading all relevant files only once
That'd be replacing hundreds of
findinvocations with 1 directory listing and then 1 file open operation per file.The actual date increment would be infinitely better if you increment 3 variables, year/month/day, separately, and have them roll over. That would get rid of almost all wasted cycles.
Of course if you had started with a") But for now, getting rid of days 32...99 and then all these non-existing months is the money maker.
But for now, getting rid of days 32...99 and then all these non-existing months is the money maker.
day > 0 and day <= 31check etc., someone would've pointed out how you are wasting time in February when there are only 28 daysAuthor at Zettelkasten.de • https://christiantietze.de/
Amazing! I've rewritten the script in python, learning programming concepts. @ctietze, your tip about reading the notes only once added rocket fuel to this little engine. I'm proud and happy. I tried to run this script on the "10000 markdown files" stress testing archive but couldn't because it requires each note to have a date (%Y%m%d) UUID in its title.
I pythonized the shell script, which wasn't easy but a keystone learning experience.
The new python script is named 'ogden.py' after @ogdenkev from the stack overflow forums, who helped me at a point where I couldn't even clearly explain what I was doing. He saw through my verbal stumbling and got me on the right foot.
Time results processing 2300 notes.
Old script
sh statshistory.sh :: 9m12.95s totalNew script
python ogden.py :: 2.48s totalYou'll want to be sure to change:
target_dir = pathlib.Path("/Users/will/Dropbox/zettelkasten/") csv = '/Users/will/Dropbox/Scripts/zkstats/stats.csv'You'll want to be sure to have:
Assets
ogden.py
Output
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
That's great to hear!
For others who want to follow along:
Install dependencies:
Then run the script via
I guess I have to work on my links") And also fix all the old links that don't use
And also fix all the old links that don't use
[[wikilink]]syntax, heh.Author at Zettelkasten.de • https://christiantietze.de/
Slightly off-topic, but maybe not, in my youth (my first personal computer was an Apple II) I learned to program the basic language. I wouldn't mind devoting myself to programming again, even if it's just for fun. Do you have any valuable resources to suggest for learning Python?
This is awesome @Will. I'm assuming that link counts being negative is a bug?
Zettler
I don't know what that rascal @ctietze modified in the script, but my link count goes positive. See above.
Maybe I should come up with a better method for count links than
## Link Count l = data.count("[[") - 1 # -1 to account for the UUID tl += lI think this method accounts for bracket tags of the style [["bracket tags"]] besides zettel to zettel links. This might be undesirable behavior.
I am thinking about it now. This method will give erroneous information if you don't use a UUID in each note. If you don't, the link count would be off by the number of zettel. I may have to look at using regex to be more specific about what an interzettel link is.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Thanks for adding the more straightforward instructions. My excuse is I'm a newbie with python, and I was very excited over the last couple of days as this came together. Packaging a python script is a bit more challenging than I've used in the past. I'm still working on getting my head around this. Maybe the forthcoming scriptability might help, or maybe Applescript could be helpful. More education is on the docket.
My comments shouldn't be taken as criticism, as many if not most novel ideas spring from a chaotic jumbled mess. If work habits are all over the place and irregular, then any type of data extraction would be suspect. One has to weigh the cost benefits and decide for oneself.
Zettelkasten Sanitation. It's the key to seeing any value here.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
I'm an old man. Getting educated, learning any new skill is part of my DNA. It brings me into a great community. Socially it is excellent, and it is very mentally stimulating.
I'd recommend Stack Overflow, sign up and ask questions. Also, YouTube has resources. I particularly like Corey Schafer's channel.
I learn best as I build, and as I learn to formulate my questions better, a simple DuckDuckGo search surfaces answers.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Thanks Will, I'll follow your advice ;-)
I got to thinking about this and I might have a solution. What form do your "old links" take? The links graph is already populated with 3 forms of "wiki links" a couple of more won't hurt. A few samples would help.
I have revised and updated the ogden.py, adding copious comments and minor changes in the links graph.
#python #stats #graphing
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
@Will it could be time for you to embark on another tool: GitHub Gists https://gist.github.com/
You can post code snippets or the source code of files there and maintain updates, with version management for a history. That could help with sharing the Python script around the web, and you only have to post 1 link ever since visitors will always see the latest version.
l = data.count("[[") - 1 # -1 to account for the UUIDThis indeed is the culprit. I'm not using double brackets in my headers, so any note without a forward link will count as -1; and my old notes have references of the") I can wait a while and then modify the script as needed for myself.
I can wait a while and then modify the script as needed for myself.
§202109300939kind. But please don't support that to not encourage use of this, unless you want to promote the practiceAuthor at Zettelkasten.de • https://christiantietze.de/
I have a GitHub account and will explore the Gists section. I recently switched to Sublime Text as my IDE and haven't yet had time to visit GitHub integration. I had been using Atom with GitDiff and GitHub.
ogden.py is saved on Dropbox. Much like GitHub, it is under version control. I just save the file as I'm working on it, and the old link now points to the updated file. I only post one link, and if someone collects the old link, it will point to the newest update.
This line has been gone from the last two updates. It was a bad idea that went nowhere.
This is the line you are interested in.
84 link_pattern = re.compile(r"(?<!{UUID_sign})\[\[.*?\d{8}|]]‹|§\d{8}")I added accommodations for links in the format of
§202109300939, not to encourage the practice but to make this script cover more use cases. And mainly for the challenge and practice.Give the new version a try and let me know.
Thanks a lot.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page