Mentions Script & Automated Draft Structure Notes

Here is how this all got started.
I was struck by an idea, "What if...?" not fully formed but enough to continue to bounce back and forth between my ears. The idea originally was, "Wouldn't be interesting to know how many times a person was mentioned in my archive?" Then it quickly morphed with, "What if there was more than one person I'd like to know how many times they were mentioned? What if I wanted this list to be keep up to date, tracking progress over time?" And it has spread like head lice ever since.
You poor souls get to be the ones exposed to my attempts at learning to code. This is an experiment and my humble attempt at coding.
This all started with a personal itch. No! Not the kind of itch soothed with an ointment. It was the kind of itch that metaphorically is the spark that ignites many software projects.
I want to create something besides a Keyboard Maestro macro and started making a MAC service with Automator. We'll see where this goes?!
The examples I use here, people and animals, are very simplistic. Originally, I thought I would use this to track "mentions" of people in my archive, hence the script's name. But I see now its utility in drafting structure notes. This script will search The Archive with a list of terms (think outline) and create the first draft of a structure note populated with the results.
I dare you to try it out and let me know how it works for you.
Please let me know what you think of this idea, even if you don't try it out.
Here are the assets from the project.
Video

Screenshot showing the results.
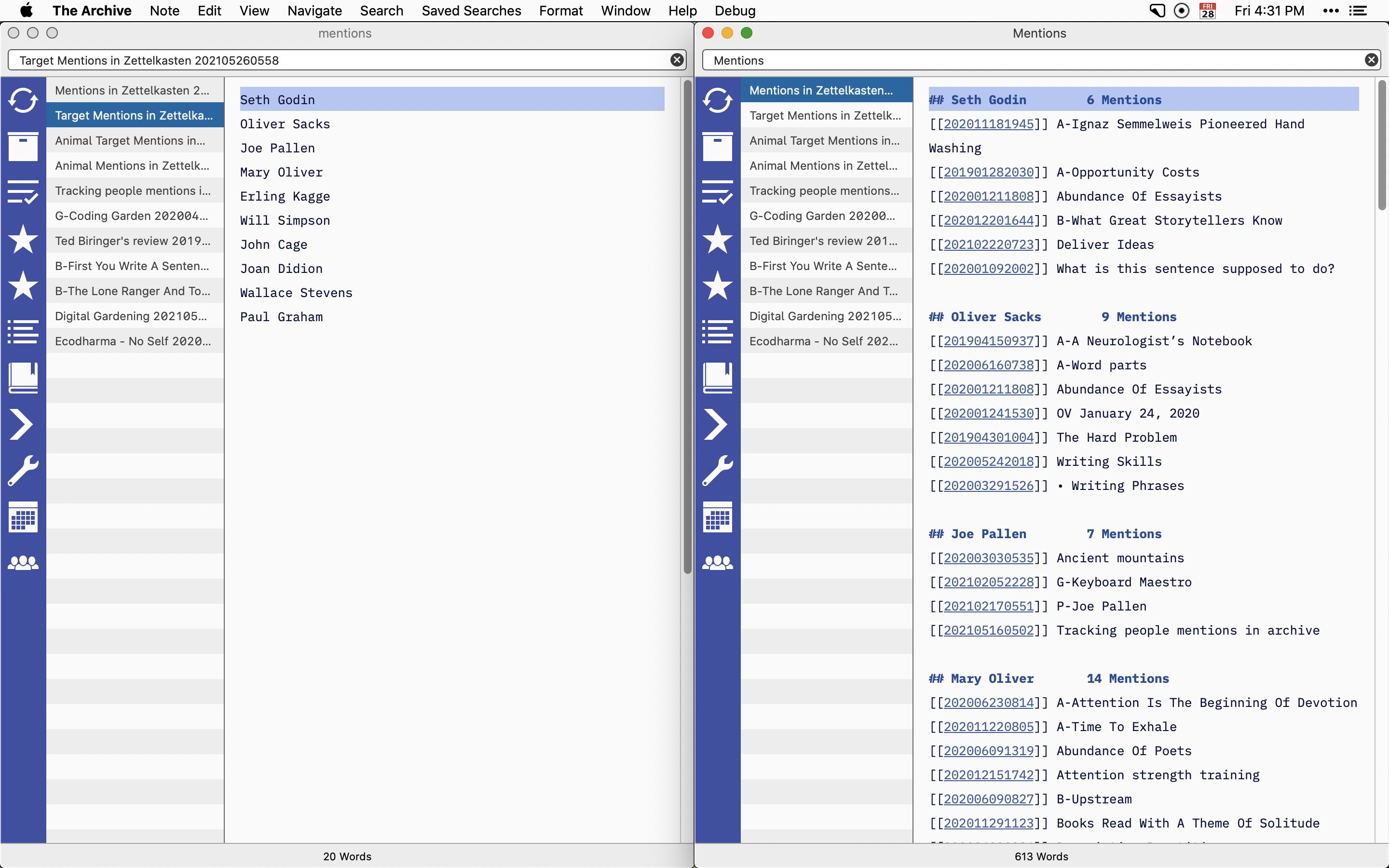
Code
You don't need the code as it is embedded in the Mention Builder Quick Action Service (below). All you need is the 'Mention Builder Quick Action Service', and with a couple of small user edits, as described in the video, you'll be good to go, I think?! I've printed it here so you can examine the code and get a chuckle at such a beginner's efforts. Comment and tips are welcome. Please help out a beginner.
# creates a zettel with names and note links (outputZettel) from reference note of names (inputZettel)
# User settings
zettel='/Users/will/Dropbox/zettelkasten/'
inputZettel='Target Mentions in Zettelkasten 202105260558.md'
outputZettel='Mentions in Zettelkasten 202105260734.md'
IFS=$'\n'
destination=`mktemp -d -t mentions`
cd ${zettel}
touch ${zettel}${outputZettel}
for line in `cat ${zettel}${inputZettel}`
do
number=$(grep --exclude={"${inputZettel}","${outputZettel}"} -iF ${line} *.md |wc -l)
echo \#\# ${line} ${number} Mentions
grep --exclude={"${inputZettel}","${outputZettel}"} -iF -l ${line} *.md | sed -E 's/(.*)([[:digit:]]{12})(\.md)/\[\[\2\]\] \1/'
echo " "
done > ${destination}${outputZettel}
sleep 1
mv ${destination}${outputZettel} ${zettel}${outputZettel}
Download zipped workflow. Don't extract on the Dropbox site instead use the  on the left of the screen and select download to get the whole workflow as a package so it installs nicely. Be sure to open Automator to change the user settings for your setup before running the workflow!
on the left of the screen and select download to get the whole workflow as a package so it installs nicely. Be sure to open Automator to change the user settings for your setup before running the workflow!
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Howdy, Stranger!
Categories
- 3K All Categories
- 152 Research & Reading
- 692 The Zettelkasten Method
- 8 Knowledge Work
- 100 Writing
- 464 Software & Gadgets
- 154 Workflows
- 731 The Archive
- 15 Plug-In Showcase
- 88 Resolved Issues
- 225 Projects Logs and Journals
- 83 Project: Zettelkasten.de
- 53 Critique my Zettel
- 171 Random
- 373 Introduce Yourselves!
Comments
@Will
Looks interesting. I'd like to try it out. I have downloaded the file "Mentions Builder.workflow.zip" and can unzip it, which produces a folder "Contents", which contains "document.wflow" and "info.plist", as well as a "QuickLook" subfolder.
How is the service "installed"?
@GeoEng51
I am embarrassed. This worked great locally and I didn't think it would be a problem to share the exported workflow via dropbox. The exported file is exploded by dropbox and you get to see the contents of the "workflow app" rather than being able to download it intact. I get the same problem with a zip file. Dropbox is trying to be helpful. I think I did find a way to share the workflow though and edited the first post.
Give it a try and let me know if it installs.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
@Will
No worries - I copied your script and pasted it into Automator, setting everything else in Automator in the same manner as I could see in your video. Then I changed the name of the ZK directory and the inputZettel and outputZettel files to ones I had set up in The Archive. I wasn't quite sure what to do then, but I ran the workflow from within the Automator and that worked fine, then looked under The Archive.....Services and saw the script listed, so I changed the target values and ran the script from "Services". Again, everything worked!
Here are some screen shots of my Automator set up and of the results. My target words were Creatures, Dreams and Death.
This is an amazing script - I can see multiple uses for it. Thanks for thinking of and then creating it!!!
One problem that I noticed is that the UIDs in the resulting list of mentions are not clickable, which they seem to be in your video. Any idea why that might be or how to change the script to get that?
Great news. I only hope that the download will work for others without the rigmarole you went through.
The clickable link problem is a reflection of the different title format we use. Switch the line in script
grep --exclude={"${inputZettel}","${outputZettel}"} -iF -l ${line} *.md | sed -E 's/(.*)([[:digit:]]{12})(\.md)/\[\[\2\]\] \1/'to
grep --exclude={"${inputZettel}","${outputZettel}"} -iF -l ${line} *.md | sed -E 's/([[:digit:]]{12})(.*)(\.md)/\[\[\1\]\] \2/'Please test this and if it works I'll switch the download.
I'm slowly working on this to automate it to make it less fiddly. But it is reassuring that someone else was able to get it to work. This is a different environment that Keyboard Maestro.
Thanks for testing.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
You are grepping all your .md files 2N times if you have N names, which can get slower as you add more files and names. One suggestion is to use egrep to search for all the names simultaneously and then only grep the output of that egrep N times, a much smaller file! For example (untested):
#!/bin/sh # creates a zettel with names and note links (outputZettel) from reference note of names (inputZettel) # User settings - zettel='/Users/will/Dropbox/zettelkasten/' inputZettel='Target Mentions in Zettelkasten 202105260558.md' outputZettel='Mentions in Zettelkasten 202105260734.md' # algorithm: cd $zettel TMP=tmp$$ trap "rm $TMP" EXIT # remove the temp file on exit # replace \n with |, and strip the last | so that search string is in the form name1|name2... search=$(tr '\n' '|' < "$inputZettel" | sed 's/|$//') egrep --exclude={"$inputZettel","$outputZettel"} -i "$search" *.md > $TMP # $tmp has it all so now we separate out counts for each name IFS='\n' for name in $(cat $inputZettel); do count=$(grep -iF "$name" $TMP |wc -l) echo "## $name $count Mentions" grep -iF -l "$name" $TMP | sed -E 's/(.*)([[:digit:]]{12})(\.md)/\[\[\2\]\] \1/' echo " " done > $outputZettel@bvs, thanks tons.
Yes, I can see where I'm gripping the entire archive all multiple times to get these results. Having a tmp file of the target links would narrow and speed up the search.
My current
time sh mentions.shfor 2k notes and 10 search phrases.I tried your code and there is some research I need to do. It looks great and looks if should work but for some reason it doesn't. In fact it produces a blank $outputZettel.
Commenting the rm $TMP and capturing TMP in a file, produces a blank file. I think this is a clue. I'm unfamiliar with this style of tmp file creation and removal. I've been using the code snippet that @ctietze turned me on to.
mktemp -d -t mentionsI also get the error
egrep: empty (sub)expression.I get the need to change the grepping for speed.
We'll work on this in the morning.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
The
TMP=tmp$$idiom simply creates a string 'tmp' followed by the process-id, which is unique while this process is running so using it as part of a temp file name works well. Thetrapcommand is used to clean up on exit.I made a number of mistakes. Here is a corrected & tested (on a Mac) version. Note that this will fail when you have so many files you run out out total size limit for args (1048576 on a mac based on
getconf ARG_MAX).#!/bin/sh # creates a zettel with names and note links (output) from reference note of names (input) # User settings - zettel='/Users/will/Dropbox/zettelkasten/' input='Target Mentions in Zettelkasten 202105260558.md' output='Mentions in Zettelkasten 202105260734.md' # algorithm: cd $zettel TMP=tmp$$ trap "rm $TMP" EXIT # remove the temp file on exit; comment out line if you want to see $TMP IFS=$'\n' # capture all mentions of all the names from $input egrep --exclude={"$input","$output"} -iF -f $input *.md > $TMP # $TMP has it all so now we separate out counts for each name for name in $(cat $input); do count=$(grep -iF "$name" $TMP | wc -l) echo "## $name $count Mentions" grep -iF "$name" $TMP | \ sed -E 's,(.*)([[:digit:]]{12})(\.md):.*,\[\[\2\]\] \1,' | uniq echo " " done > $outputYes - that works perfectly - thank you!
Do you know where the *.workflow document is stored? Even though I save the Automator script, I can't find it on my computer or in the cloud.
I can find it using "recent files" from within Automator, but I don't understand why I can't find it otherwise. When Automator starts up, it wants you to open a file, but the default is it's icloud directory, which doesn't have anything in it.
Oh my gosh, @Will - this Automator script is amazing. I hope others try it out.
You have a very inquisitive and creative mind!
@bvs, WOW! A huge difference. It feels snappy now. I hope I learned the lesson about grepping and regrepping and the time costs.
Your improvements
My old multi grepping script
When I
echo $TMPall I get istmp58657. Is there a way to see the contents of $TMP?Is the limit 1048576 the number of files or the bit size of the buffer? Either way, this seems huge.
My
ARG_MAXis much smaller??Is this a setting that can be changed?
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
This "quick action" is stored in your
~/Library/Servicesdirectory.Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
[For some reason my original reply got deleted when I tried to edit it...]
Comment out the
trapline.Bytes. If your average file name length is 24 bytes + 8 bytes for the ptr (argv is an array of strings), With your ARG_MAX being 262144, you can have 8K files!
May depend on amount of physical memory or some other parameter. I don't really know.
No. The usual work around is to use find and xargs. Something like
@Will - yes; I see it. I wonder why Spotlight Search couldn't find it. Does it purposefully not search your Library files?
~/Libraryis hidden in Finder by default, and indeed also excluded from Spotlight search.Author at Zettelkasten.de • https://christiantietze.de/