Two Questions about Zettel Structure and MetaData

I am reviewing the structure I use for my zettels, mainly to provide some agnosticism in the software I use to read and edit them. I have two questions about this and would welcome comments from forum members.
1. Important MetaData
Several years ago, after reading through comments on this forum, I settled on the following simple structure:
First line: Combined Unique ID and Title
Second and third lines: Metadata
Fourth line: Tags
I use @Will 's Keyboard Maestro macro to create the "empty" zettel file. For example, here is a recent zettel I made to capture a personal history item (between "Start" and "End" but not including those words).
Start
202406232104 Memories of Braefoot Valley People and Places
[[202406232104]]
06-23-2024 09:04 PM
tags: #Unfinished #Unlinked
The main text of the zettel goes here.....
internal links:
external links:
End
The title line is precisely the same as the file name, although later, I might adjust it to be more descriptive of the content of the zettel. I don't expect I will do that with this particular zettel.
I'm wondering if the above zettel structure is too complicated for my purposes, that is, if it couldn't be even more simple. I can't recall why I have the two lines after the title. Neither seems to have any useful purpose, and I'm considering removing them.
What do you think about just having a UID/title, tags and the internal and external links as the template for an empty zettel?
2. First line structure
When testing an import of my zettels into other software (I've tried this in NotePlan and Logseq), I see that the first line of the zettel is taken as the linkable item, not the file name or just the unique ID (which is what The Archive seems to do). So if I wanted to make my zettel structure more compatible with other software, I might put only its unique ID on the first line or I might continue to use the current practice but with short file names (created using @Will 's macro) and then add a longer, more formal title on the second (or a later) line.
(Note that I keep it simple and use the time stamp as my unique ID; I don't follow Luhmann’s notational system.)
Do you have any experience with (or just an opinion on) this? Again, I welcome anyone's comments, but I am particularly interested to hear what people who use perhaps several different pieces of software to access their ZK have to say.
Howdy, Stranger!
Categories
- 3K All Categories
- 152 Research & Reading
- 692 The Zettelkasten Method
- 7 Knowledge Work
- 100 Writing
- 464 Software & Gadgets
- 154 Workflows
- 730 The Archive
- 15 Plug-In Showcase
- 88 Resolved Issues
- 225 Projects Logs and Journals
- 83 Project: Zettelkasten.de
- 53 Critique my Zettel
- 171 Random
- 373 Introduce Yourselves!
Comments
Metadatas are quite an interesting question indeed!
With time of use, what I keep are :
I don't use the last one to classify my note but to give some context. I can also search for "name of an author + "citation" type" to find what this author wrote that interested me.
Whatever the software I use, I use this metadatas.
Logseq as an outliner works its own way, it focuses on blocks rather than files, so you'll find a different format of metadatas : as in OrgMode, you'll type "property:: value" like : "date:: 2024-06-27" so I add my metadatas at the top of the note, right under the title and the name of the file.
I used Obsidian which works with pure markdown and as they introduced a nice UI to work with metadatas, it is still YAML frontmatter with its own syntax. So my metadatas was at the very top of my notes :
---uid:
tags:
type:
---Title of the note
On paper, I wrote the title with UID. At the top right of the card, I noted the type of note with a colored pen. Under the title, I introduced some tags.
I also like to add a "context" part right after the main title. "While reading [[this book]], I felt like the author mislead his audience with wrong informations so I... "
It is what works for me.
Maybe you need more simplicity right now and complexity could come later.
Maybe you can be agile about the structure of your zettels, with some more structured than others when needed. For example, if I take a note about a book, serie, film or a video game, I'd add the "publishing year" line of metadatas and a link to the author/studio. Try without some elements, introducing it in some notes and see how you feel, what are the consequences of working with and without them?
YAML is a plain-text standard that works in a lot of applications.
Example from my default note template:
The first line after the YAML is the note title equal to the file name minus the file extension.
YAML is referred to as frontmatter and is not displayed or printed in most software that can preview markdown files. However, YAML provides many additional features, such as page sizes, fonts, variable replacement, and so on.
This should not affect how another app displays the note. The problem with application interoperability is the link formatting.
Maybe a specific example would help.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Yes, I'm just getting used to "properties" in Logseq. It introduces flexibility in that you can use it or not for a particular note, and of course search (or set up queries) on properties.
I like this arrangement, particularly keeping the uid separate from the title.
Yes, good suggestions. Flexibility or agility in the use of metadata is a good idea. I've been a bit rigid in my thinking about that, but your advice points me in a better direction.
@Will said:
Generalizing on what Will mentioned: In my view, the most important principle is to use a metadata standard (e.g., YAML) that you can programmatically convert if necessary (e.g., if you need to import into a software system that uses a different metadata standard) using any relevant transformation tool from regular expressions to Pandoc. As Loni said, some notes can have more metadata fields than others.
@GeoEng51 In the spirit of simplification, the screenshots of the introduction are still how mine look: https://zettelkasten.de/introduction/#the-anatomy-of-a-zettel
Reference definitions go at the bottom, but references and links are being made inline where appropriate. See:
Author at Zettelkasten.de • https://christiantietze.de/
Thanks, @Will . This is similar to what @Loni suggested and I will adapt to suit my use cases.
You are so right here. When I try to import my zettels into both NotePlan and Logseq, they treat the first line as being the actual item for the link - keeping in mind that my first line is just a UID and title, as shown in my original post. I haven't tried importing zettels that contain YAML at the beginning, in the format you have indicated. I'll try that and see what happens.
When I import an existing zettel, both NotePlan and Logseq create a note that uses the first line as the formal link for the zettel. Here is an example of one of my early zettels (selected for its brevity):
202006091436 Effective Ministering Principles
[[202006091436]]
tags: #Ministering #ManagingTime #Spiritual_principles #List
internal links:
[[202006082330]] Leading by doing is a good principle to keep in mind
[[202006242036]] This link is about foreordination
external links:
https://www.churchofjesuschrist.org/ministering?lang=eng
Here is an image showing how it gets imported into NotePlan (sorry; screen is not high enough to capture all the information):
and here is how it is captured in Logseq:
The problem with this type of import is the creation of additional, empty notes:
[[202006082330]] Leading by doing is a good principle to keep in mind
"[[202006082330]]" gets turned into an additional, empty note.
The net result is the same: I have to change the structure of my zettels to get them to import cleanly into other software. For one, this would require replacing the thousands of links already in my zettels of the form [[yyyymmddtttt]] or, alternatively, using only UIDs of that type in the first line of my zettels.
The normal way of creating a link in both NotePlan and Logseq is to type "[[" and then the beginning of a UID, and the software brings up likely candidates, one of which you can select. In The Archive, I search on a specific term, find the zettel that I want to link to, copy the UID and paste it into the "internal links" section of the new zettel.
I've accepted the idea that I will need to rework my entire ZK so that the zettels can be read (i.e., imported into) any ZK-like software. The question is the right way to do that and the simplest way to modify the format/structure that I already have.
Herein, at least in part, lies my problem. I don't know what The Archive actually does when I click on a link like [[202406271607]]. I know it shows me the related zettel. However, does it search all the file names in your ZK directory for the one that contains that UID and then return that zettel? Or does it search the first lines of all my zettels?
It's nice to have links like [[202406271607]], because that simplifies creating links in our zettels. However, as mentioned in my reply to @Will , when I have all of these UID-type links in my zettels, and then I import those into (say) Logseq, it creates empty notes for each of those UIDs. If I click on the UID-link in a zettel, I see both the original zettel that I wrote and the empty note.
One way around this would to have only the UID in the first line of each of my zettels, which wouldn't take too much work to accomplish. But I don't know if that is the right approach.
I don't know how to modify every files, but there might exist a Python script to accomplish modification on a batch of file. I am not enough advanced to give hint to you however, I am sorry.
What would be an maybe acceptable solution would be to use UID :
I don't really know if you are free of putting any title into the Archive, but you can do it with most of software who works with markdown files.
I don't find your note complex, is even simpler than mine
I don't use a code.
As header I have title (in Obsidian is outside the window, but is a part of header at a logic level), creation date and tags, and two other fields.
A "type" that helps me to classify notes by type (in my Obsidian I don't have only the Zettelkasten, so I need to discriminate type of notes) and a "domain" field, that contains the higher level theme of the note (developing photography, and so on) (I don't use very often, anyway, I can live without).
Instead of having all links at the botom of the note, in top position I have only special, few links. which they form relationship of type "parent", if any.
Obsidian uses YAML and Markdown, so (I hope) it should be rather future proof
this is my model of zettel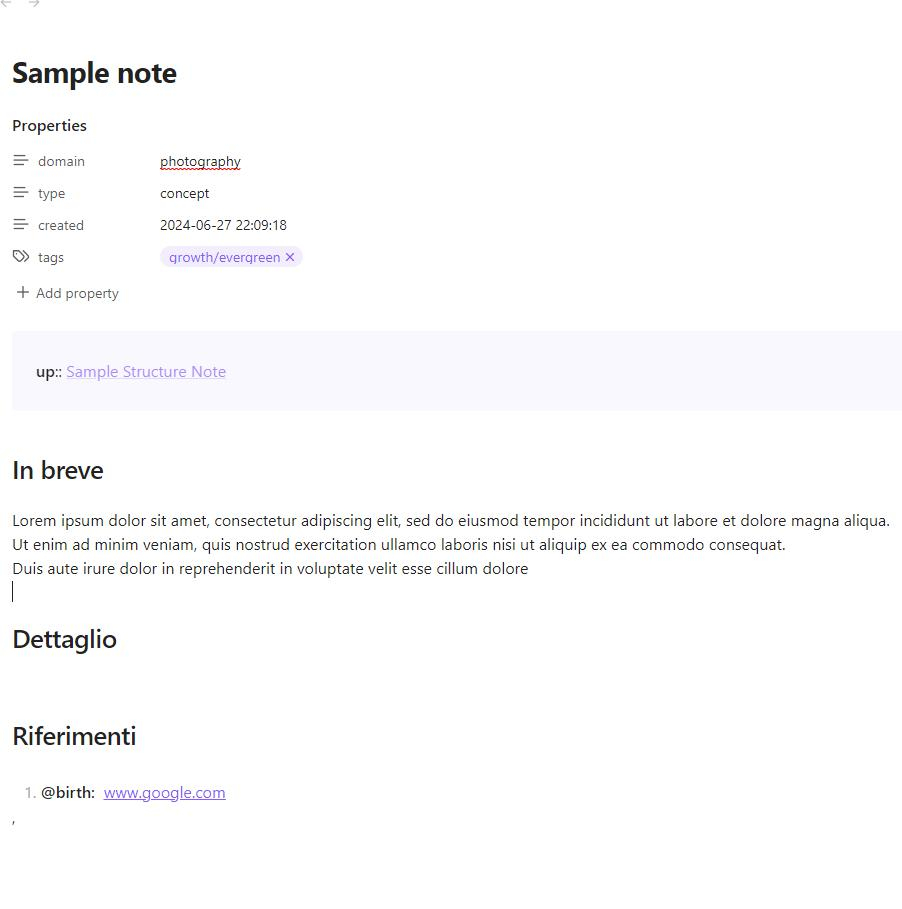
this is the markdown:
@GeoEng51, changing the link format is tricky. I was one of the evangelists who suggested using the UID as the link. In hindsight, using the filename would have been more advantageous. Although it would have required keeping the filename matching the note title, this problem, which seemed insurmountable then, is now manageable. I didn't foresee the pros and cons of changing the link format. For those who stick with The Archive, the shorter UID link works well. The Archive originally sets the link to the filename by default. While not elegant and prone to breakage with title changes, the filename links are more compatible across different software.
Switching to UIDs made sense because the UID remains constant, unlike filenames that change with iterative title updates. Unfortunately, this change makes my archive incompatible with most software, except perhaps org-mode.
I’ve considered changing my link format again, but I need to understand the implications and fully understand how to future-proof my archive.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
@andang76 Thanks for your comments!
@Will I'm also having the same anxiety about changing my link format—trying to find something that is as future-proof as possible and compatible with different software on the market (at least, that I might use).
I had a look at the article on YAML that you referenced and noticed that the format for keys is:
key: value
Where "key" is followed by one colon. I think I will adopt that approach, but sparingly. This is similar to page properties and block properties in Logseq, except that the key is followed by two colons, as in
key:: value
@Loni, I used to program in Python. I guess I'll have to dust off my skills, as I'm sure there is a script that would handle making certain changes to all of my Markdown files / zettels.
At first, I was skeptical about YAML metadata. Eventually, I settled on at least two YAML variables for compatibility with Zettlr, Pandoc, and Obsidian. The variables are
title:andreference-section-title:, respectively. This choice might be compatible with Logseq--I have to check again. I'm somewhat mystified by what Logseq produced the first time I tried to load my Zettelkasten directory.Like @GeoEng51, I included the ID in the title variable. In keeping with my practice of sharing my least valuable Zettels, here is one with the lyrics of a song I "heard" with the fan going. (I experience auditory illusions.)
If I need to add to the $(\LaTeX)$ preamble, I use the variable
more-header-includes:defined in my lightly modified Pandoc $(\LaTeX)$ template, as in this example.--- title: CATS2024062521 A box-product of categories reference-section-title: References more-header-includes: - \usepackage{quiver} --- # CATS2024062521 A box-product of categories ...Those interested in a graphical editor for tikz-cd diagrams in $(\LaTeX)$ can visit Diagram URL - q.uiver.app.
Zettel GitHub. Zettel Wiki Erdős #2. Problems worthy of attack prove their worth by hitting back. -- Piet Hein. PROBLEMS. Grooks, 1966. CC BY-SA 4.0.
@GeoEng51 Which note is displayed is determined by a filename prefix match, with the fallback of "if there's just one result, show that".
Link-as-search produces the search query
12345when you click on12345and will12345".Migrating the short ID's to full filename search should be simple, because in this direction you only ever add information. For you and me, the number is an ID; for a search, it's just any phrase. If you search and replace across all your notes the occurrences of "
[[1234]]" with "[[1234 The title here]]", that should do the trick.Addition is often a safe operation that can be reversed. Replacements with something else entirely would be harder to undo.
I can aid in the development of a Python or whatever script if anyone wants to tackle this.
For anyone trying this: Please work on a copy of your Zettelkasten, not the real one. Zip the folder. Do backups. Use git. Make sure you can get back to your working copy from 'before the script' within minutes.
Author at Zettelkasten.de • https://christiantietze.de/
I've went through this same dilemma, especially during the times of discussions that Will was alluding to such as during the "link as search" vs. "link as direct" discussion. I too wanted to use my archive with other programs but all the other programs were gravitating towards functioning as "link as direct."
For me, what helped finalize my decision to stay with UID's ("link as search") were two reasons:
So, yes, based upon my decision, I've lost the ability to test out many other programs that have adopted the "link as direct" method. But I still consider the system I've chosen to be future proof even if it's not completely compatible with the majority of the apps today.
I'm still at the lowest common denominator in that if The Archive, Zettlr, or any other program using the "link as search" method goes away, apps like obsidian can convert the format for me if I'm forced to chose or use a plain text editor. But that won't work the other way around. That's future proof to me.
If I were being honest, I'd confess being attracted by all the talk on the internets of cool new apps, the shiny new thing syndrome. Couldn't I be an adult about all this? Something about your post, @Darryl, changes my perspective. I'm happy where I am. I don't have to spend time like a butterfly, flittering like a drunk sailor from app to app. I have a small backlog of notes/ideas in my proofing oven, starving for attention. I could be spending my time with them. I have a long "want to read list." These notes and books will add value.
This is a convincing argument. Today, I tried navigating my archive for the first time in TextEdit and IAWriter. I found it doable in combination with Finder, and I could reproduce the functionality I need for zettelkasting. This is likely the case with many other text editors. The one thing that would make the "link as a search" work better in other apps is having the link the same as the file name and I've begun to wonder about the value of a UUID in the link.
I'm not sure what you mean by "UIDs basically function as footnote markers." Are you referring to the position of the link in the note? The position of the UID in the link? Or something else?
Rather than miss an opportunity to test out any of the new programs on the market, I am going to take a fresh perspective. I'm staying in the "link as search" camp and will try to avoid being distracted by the shiny new tools all the 'cool kids are ranting about'.
This is a second convincing argument.
Thanks, @Darryl, for your clear perspective. I appreciate it.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
@ctietze Your explanation was very helpful; thank you. You've inspired me to start working on a Python script, which I will share when it works. It may not be elegant, but hopefully, it will do the job
@Darryl and @Will Thanks for your perspectives on this topic. I'm not sure I appreciate the pros and cons of "link as search" and "link as direct" yet and I will have to think about this more.
Outside of future-proofing, two considerations drive me:
I thought I'd found a solution to both of these wishes in NotePlan, which is a remarkable piece of software. However, I ran into the issue importing all my ZK files into it that I described in an earlier post in this thread.
I thought Logseq might be different, but it seems to have a similar issue (notice I didn't say "problem").
Both NotePlan and Logseq produce regular markdown files stored on your computer.
I take it that the concern about "link as direct" software, even when it produces markdown files, is that it stores "extra" information in those markdown files, which it uses to track the links and for other functionality? For example, the "collapsed::true" line in the following text is not part of the original text, but it's purpose is clear:
2024.06.25 Second day of site tour.
collapsed:: true
- Left ZZZ at 7:30 am.
- Arrived at XXX at 8:30
- Planning to do a ground tour:
- AAA and BBB in the morning
- CC and DDD in the afternoon
or another example:
Background - Comments from XXX
id:: 666b32bd-aeed-465e-ab3c-ae92f0ead9c4
Here, the last line is "extra text", not part of what I typed in or what is viewed on the screen, but used by Logseq to locate a link to this block.
It seems what Logseq is doing, and perhaps by logical extension what other "link as direct" software is doing, is still searching the text file database for terms, but in their case, for the additional terms that the software itself has introduced into the text file.
I can't see how this would compromise using a plain text editor to search through the markdown files, but seeing the additional text in the files might be distracting.
I'm sure I don't fully understand what Logseq is doing to establish links and provide other functionality, but it must be something close to what is described above. Does that bit of information change your ideas about the "link as search" versus "link as direct" discussion? It seems that in both types of software, a "link as search" approach is being used but in one case, the search is on "extra" terms introduced into the text file by the software.
Completely agree! Came to the same conclusion.
I've tried with AIWriter as well and even emailed them prior to the release of their implementation of wiki links advocating for link as search, but alas, to no avail.
Although I do use UIDs in different fashions, by this I mean: when I am writing a note and referencing another, I write in such a way that the UID of the note I'm referencing is treated as the footnote marker for the content I am writing, and the content of the referenced note would be the text of the footnote. I do this not just so I can reference other notes in a contextually logical fashion (at least in my mind), but it also helps to trigger when I need to create a new note (which can be tangential, evidence, argument, etc).
Great way to frame it!
You're welcome. Just passing along the favor, I suppose, from all I've gleaned from you over the years.
You're welcome!
Just my two cents here:
I used to think and strive for the same thing. But one day I realized: no other hobby or vocation really has this mindset.
There are all kids of different tools and mediums that are used depending on the vocation or hobby because they are necessary/more efficient/etc. Take a mechanic for example: a mechanic has various different tools for different purposes. One may argue that they are looking for one toolbox ("piece of software") to keep their tools in. Okay, but what about when the need grows to require a jack, car lift, or other tools that cannot fit into a toolbox. Okay, now we need to look for a garage (yet another piece of software that can encompass even more, increasing the requirement). But what if you need to do administrative work requiring an office, what if you want a showroom, etc. Where does it end?
Of course, the illustration eventually breaks down. But I hope it conveys the process that I had to go through to be content with using (what I consider for my purposes at the time) the best/right tool for the job.
This can apply equally to other hobbies and professions as well in the arts, sciences, etc.: I mean: Why should I think differently as a knowledge worker? Why can't I just accept the fact that I need multiple tools to be the most efficient? I (finally) have.
Take Noteplan, for instance. I use it as well. Yes, the owner markets it as a Zettelkasting tool as well. It may work for him and others and that's great. He's promoting his product. He has to so he can have a wider appeal. It's marketing. But for me, it's not the best tool for my Zettelkasten. That's fine; it doesn't have to be. I use The Archive which is for now the best tool for the job for me. And when there are apps that are best used for multiple functions (e.g. Devonthink for me), then great, that's a plus!
But in the end, I just use the best/right tool for the job and I use it until it's not. That's when I start looking for something else (or for other factors like "future proofing" if I think it's necessary and have the time). I do this to safeguard my own time knowing my propensity to tinker with technology. Otherwise, I'll be chasing every new app that comes on the market distracting me from my other (more important) goals.
Yes, I understand and pretty much follow that philosophy. Right now, I use NotePlan for tracking my work and general planning (along with a calendar - BusyCal), The Archive for my ZK (which includes both personal items and, on occasion, work projects), and Scrivener for taking notes in work meetings, from which I produce memos and reports. Each tool has strengths and weaknesses and gets used where it's best suited.
But I continue browsing new software to see if something interesting is out there. Usually, it's a quick trip to a website, and it becomes immediately evident that there is nothing I want to use. Once in a while, there is a product with intriguing possibilities, and I will find/make some time to do a deeper dive. That is how I moved away from Things and Bear and started using NotePlan. Now, Logseq is sufficiently interesting for me to try it out.
I don't see this process as wasted time, but I firmly believe that hardly any time spent learning is wasted. It's always a matter of getting important things done first and then looking at interesting stuff with no clear, immediate payback later. Being semi-retired, I have the luxury of dabbling a bit more than most.