What happens at the intersection of an idea?

Answer: Ikigai
I've been trying to structure my procrastination. I call it positive directional procrastination. These are some of the results.
@thomasteepe has got me thinking about tools for idea creation. Even though this one is specifically a digital one, I still want to credit Thomas. Maybe he'd rather I not mention him, but oh well. Also, @bradfordfournier's idea of a label for zettel that lives on the edge of more than one graph is intriguing. You have to find them before you can label them. This is hard to do when you have 2237 zettel.
At a point in the thread Multi-edges / Named Links / Sub-graph: a means of capturing fluid associations I got excited about the idea of discovering what connections intersect at the edges of thought maps.
I twirled off on a tangent, exploring zsh and shell scripting. I have come up with something rough, as pictured below.
My thought process is that structure notes are the hubs of idea matrix. Individual zettel from one thought map that appear on two or more structure notes represents an idea collision. I created a script that finds these collisions. In v0.2, I used book and article notes, basically structured notes built on a book or article. In v0.3, I eliminated them and got a smaller, more focused list. I'm not sure which will have more pixie dust.
Do you have any ideas? Do you think this is lame, shit, or misguided? I've gotten stuck, fixated on for loops and while loops, and trying to use awk for formating. I what to push this out into public and work with the garage door up.
This is close but still not there. Every idea map is made up of zettel. Each zettel can be linked to a different idea map. That represents a collision score of 1. If a zettel links to two or more idea maps, then it gets interesting. That represents a collision score >2. The larger the idea map, the greater the likelihood of finding zettel with a high collision score. A higher collision score means a zettel with more magical pixie dust, more relevant, more mature, more useful.
Ideas for v0.4
Use #article #book #garden #structure-note only remove these zettel from the output, leaving only atomic notes.
(in v0.2, there are two atomic zettel, in v0.3, there are five atomic zettel)Focus exclusively on the atomic zettel collisions leaving out the structure note to structure note collisions.
- Assign a score based on the number of collisions and size of the idea map.
- Figure out a way to add the target note names and separate links for target note and idea map.
- look for idea maps that are not part of structure notes to be included in the tally.
- Many of the collisions are structure note to structure note. The jury is still out on whether or not this would contain any pixie dust.
v0.2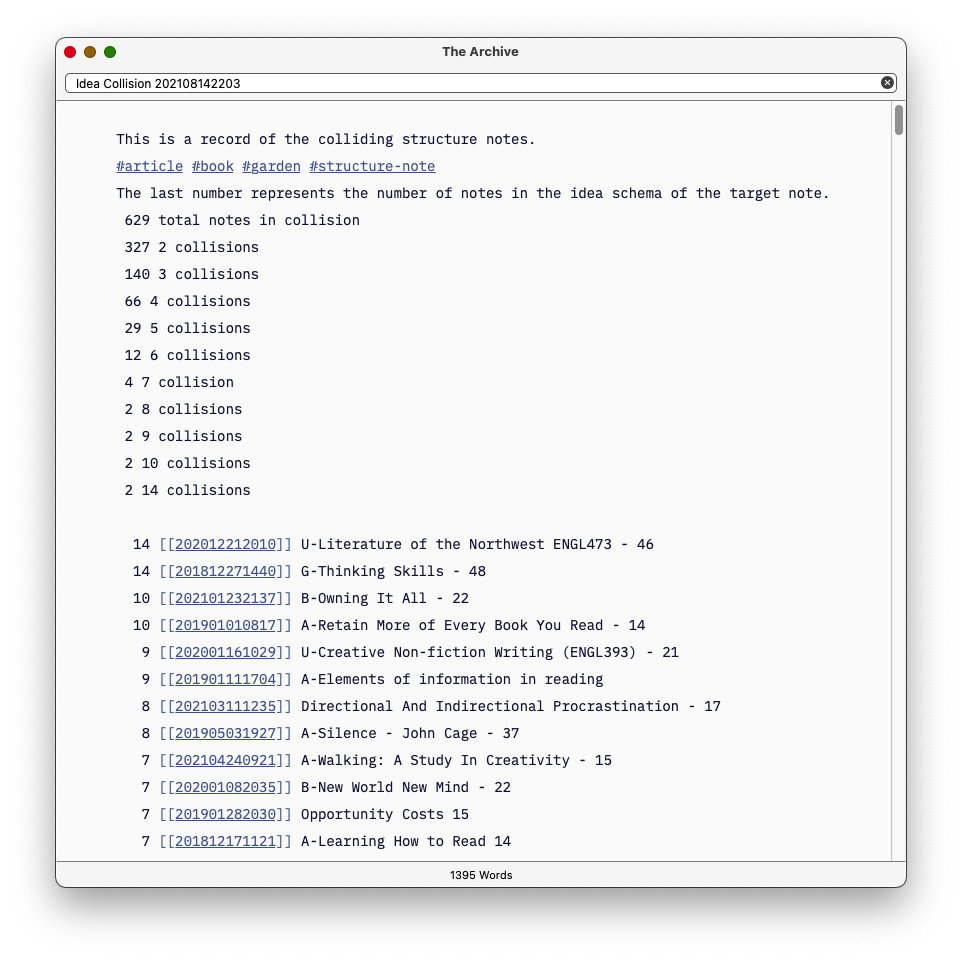
v0.3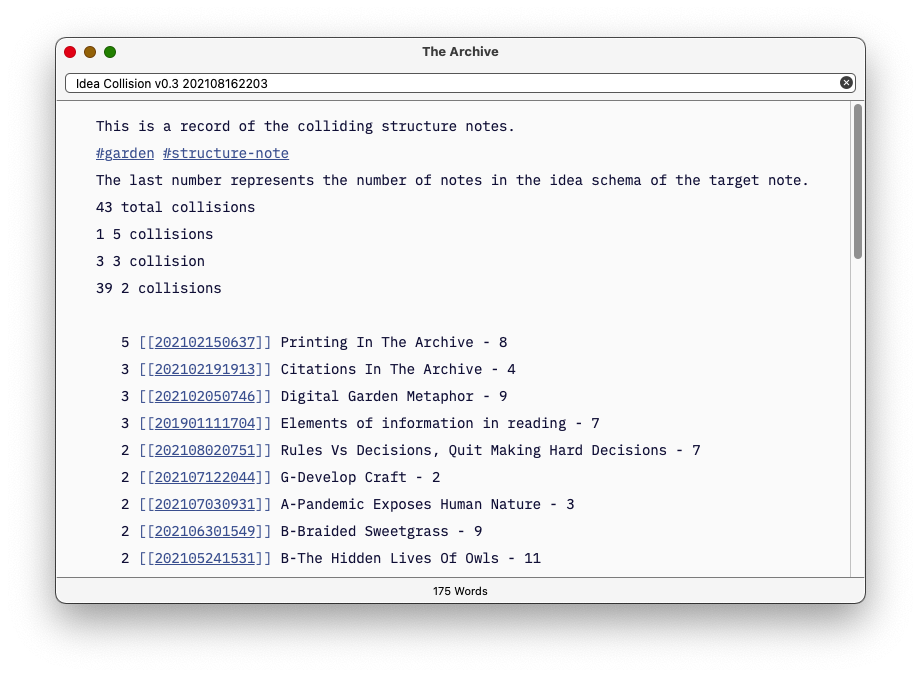
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Howdy, Stranger!
Comments
If i understand correctly, what you are interested in is a list of notes, created from the intersection of 2 or more hubs / tags. Is the score board included in the final version? I'm not sure of its purpose.
I think i would simply tag each note by
i love itandi'm great at itand list the logic and of both.my first Zettel uid: 202008120915
@zk_1000, every note has meaning and is part of my general knowledge project. Some notes are more relevant than other notes. I've always been fascinated with the idea of "scoring" my notes as a reflection on their relative relevance or usefulness. @bradfordfournier's idea of a label for zettel that lives on the edge of more than one idea graph is intriguing as a way to target atomic notes with the most inter-idea connections.
A simple tagging strategy is really a nonstarter when faced with a pile of notes (2247). Tagging all my notes in any way meaningful way would require more time than this project deserves. Especially considering that this project might not reveal anything of value.
I do think there is value here. Think of some of the graphs of the interconnections we've seen here.
They have always struck me as messy and a data overload without providing any knowledge or information. I'm proposing to look only at those atomic notes that collide with 2 or more idea graphs or idea threads as they already exist in my ZK. In initial trials, this turns out to be about 50 zettel in a zettelkasten of 2247. These 50 vary in connectivity from 6 to 2 idea interconnections. I'm interested in discovering the few notes that have 3 or more idea collisions, an even smaller subset of all the idea collisions. These atomic zettel must have some secret sauce. At least it is worth checking.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
It would be really hard to track this, but it’d be interesting to see what sequences of notes you go over the most. Similar to a retrieval route strengthening in the brain after recall practice
Yes, this might be hard. Where I put my attention is who I become. I can let this happen willy-nilly or take some responsibility and watch where my attention gravitates, not going unconscious, police my attention, keeping it from devolving, focusing on building character.
Character building does not get the attention it should.
What I'm looking for with idea collision are edge cases where two ideas mix. This is an area where new and novel ideas could be annealed. The question is how to find and rate the likelihood of a new and novel idea surfacing. This is only possible with a critical mass of notes.
A rating system where the number of collisions times the first or/and second-order links.
Think about this. If I use all the structure notes as the bases for finding collisions, each structure note being an idea hub, I'd want the links to outside structure notes and not "inter structure note." That way, I'd see only those notes that were referenced by two Idea Hubs.
Maybe this is a Don Quixote'esk endeavor. There might not be anything there there.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Reading your original post made me think of the following. It may not be quite what you are looking for but ought to trigger some new ideas to explore in your search!
How about an inverted index? You create a document with lines like
word1: (file1, position1), (file2, position2)etc. for all the words in all the notes. Then you create a similar inverted index for phrases. For example items for"idea collisions", can be created by checking for items like"idea": (file1, position1)and"collisions": (file2, position1+1). This then becomes"idea collisions": (file1, position1) ...and so on. Then you sort by the longest phrases, remove all lines with exactly one (file, position) tuple and then do a secondary sort by count of tuples or some such. Once you have the word inverted index you can slice and dice it different ways.This is the general idea. You can reduce the items to process by filtering out common english words etc. Or you can tag important phrases somehow and process only tagged phrases. You may also have to do some simplification e.g. treat collisions the same as collision and other such things that typical search engines do.
Motivation:
[[links]]are created manually. The above may give you candidates to create new links. In essence you are finding similar phrase associations.The zettelkasten software Zettekasten^3 has a similar feature, whereby you can add keywords metadata to a note. Then whenever you create a new note, you can ask it to suggest keywords, whereby it will match existing keywords with your notes text.
Indeed this is triggering ideas! Thanks for the time and interaction.
Inversion is an interesting idea. Mathematician Carl Jacobi, solved hard problems by following a strategy of man muss immer umkehren or, loosely translated, “invert, always invert.” 1 I'm also thinking about the idea of exclusion, but I'll save that for another time.
What are you thinking when you say "position 1" and "position 2"? Are you suggesting the position of a word or phrase in a note might be relevant to the idea's interaction with another idea? Or am I missing something?
Removing and re-sort like this sounds confusing. I don't understand.
Getting candidates for linking is a noble goal and the precursor to the exploration of idea collisions. We'd have to have a deeply linked zettelkasten before we can look at where ideas touch. I think I get what you are alluding to. Instead of using links as the point of collision, look at keywords/phrases and see where these appear in different idea graphs. Using links as the touchpoint in this exercise makes more sense because the link, which I manually created, contains an essential part of the idea itself.
This is the difference between looking to establish connections and examining established collisions. These take two different mindsets. Two different tools for discovery. Have two different purposes.
Many math textbooks claim that “invert, always invert” was one of Jacobi's favorite phrases. The oldest source I could find was the Bulletin of the American Mathematical Society, Volume 23. 1917. ↩︎
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Just split up the file in words and number the words sequentially. So for example if the word “idea” appears as the first word and two more positions, 5 & 22, in file foo and position 7 in file bar, first program would output
idea: (foo, 1), (foo, 5),(foo, 22), (bar,7). The next program in the pipeline can detect phrases and output them. For a phrase the position is the same as that of the first word. The position is only maintained to detect longer phrases or to detect nearness, or if you want to print out some context around them. You can ignore positions otherwise.That is to remove all uninteresting words and phrases, such as them appearing in only one file or very common ones. The sort is to put the phrases appearing in most files first. I think the explanation seems harder than the actual steps (if you were to actually try it out)!
Indeed.