Script to print all tags from .txt files (run from archive directory)

#!/bin/bash find . -type f | grep -v '/\.' | xargs grep -IEoh '#[^ ]+\s?' | sort | uniq -c | sort -r
explanation:
- finds all files
- removes any files starting with
/.(hidden files) - for each non-binary file, finds all lines matching
#and any number of characters up to the next space and returns this part of the line (the tag) - creates a unique set of tags including the count for each unique tag
- sorts them by the count
output:
18 #recipes 11 #music 7 #books 6 #songs 4 #talks 4 #inspiration 3 #hacks
Howdy, Stranger!
Categories
- 3K All Categories
- 153 Research & Reading
- 695 The Zettelkasten Method
- 9 Knowledge Work
- 100 Writing
- 465 Software & Gadgets
- 154 Workflows
- 731 The Archive
- 15 Plug-In Showcase
- 88 Resolved Issues
- 225 Projects Logs and Journals
- 83 Project: Zettelkasten.de
- 53 Critique my Zettel
- 171 Random
- 373 Introduce Yourselves!
Comments
I'm getting:
xargs: unterminated quoteMe to.
xargs: unterminated quoteWill Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
It works fine in simple folders but does break down in my archive, too. Is it the amount of notes? (xargs and piping/stdin should allow long lists, as opposed to passing a lot of parameters) Is it special characters in some file names, like single escape sequences?
Author at Zettelkasten.de • https://christiantietze.de/
In looking closer I find that the script pucks on my whole archive also. Research (google) shows that note with quotes or apostrophes causes problems. Also testing on a test archive I find it requires also no spaces in the file name. The script also reports double and triple and quad "#" when found. This seems a great start. I use a Keyboard Maestro script to create a note in my archive that lists all the tags (clickable) used but it doesn't count the number which I think would be useful.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Right, that makes sense, I should have thought of that when reporting.
Y'all are gonna make me buy KM if you keep doing stuff like this. I thought I was getting along fine with my Alfred text expansion scripts but noooo...
Yay! Went back to my Keyboard Maestro script and added the number of times a tag was used and still sorted alphabetically. Bit of a challange to get the final sorting the way I wanted. Sort wants to sort numerically by the first charater of the string.
This will work in conjunction with Keyboard Maestro or as a cron job. There may be other ways to incorperate this "Tag Cloud".
Here is the code.
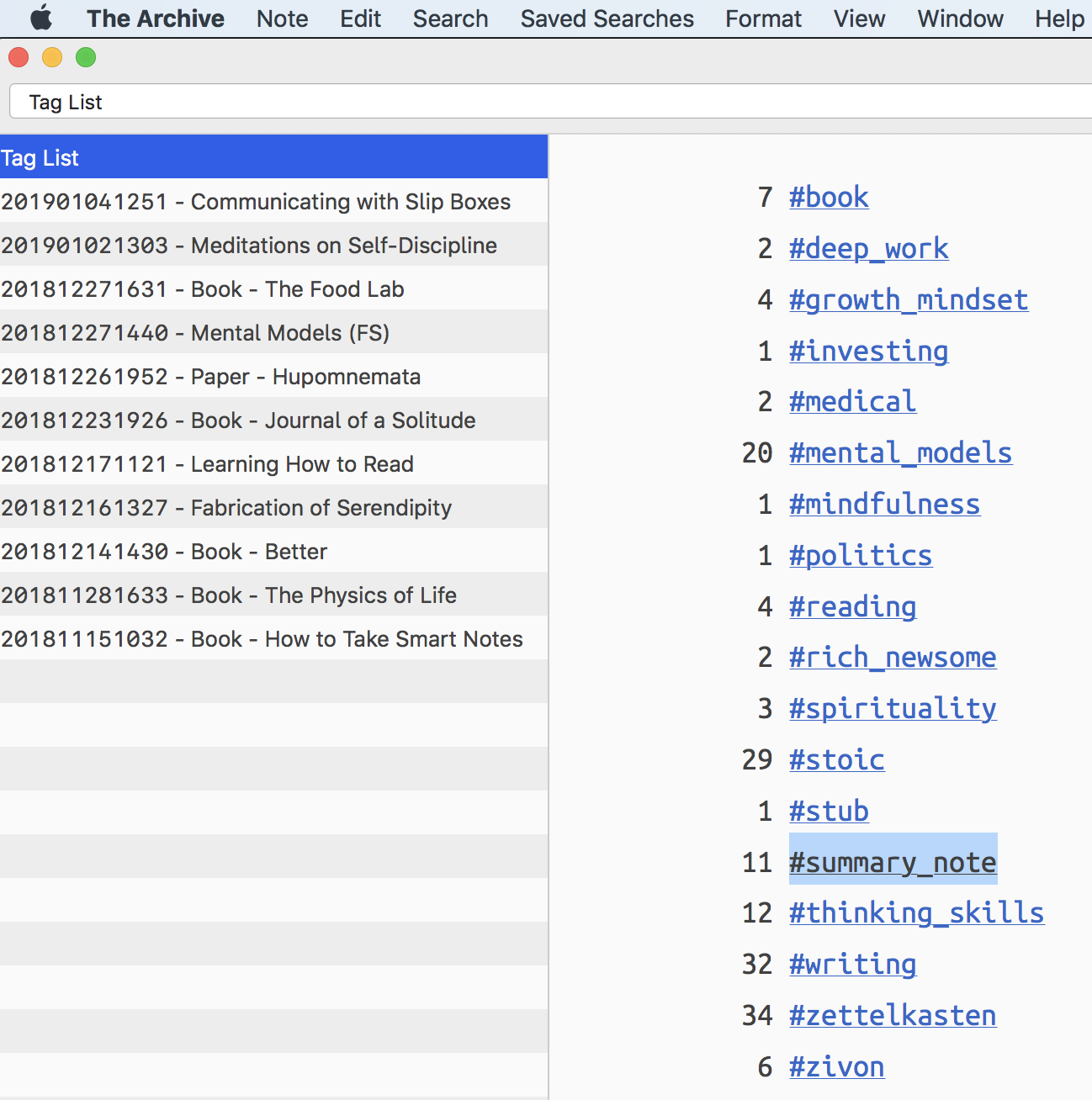
cd /Users/will/Dropbox/zettelkasten/ egrep -ohsr "(?:^|\s)#[A-Za-z0-9_ÄÖÜäöüß\-]+" -- * | sed -e 's/[[:space:]]#/#/' | sed /^[^#]/d | sort | uniq -c | sort -t# -k2 > "Tag List.txt"Here is the output.
Thanks @onlyskin for the kick to work on this.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Great stuff! Here's the Regex I use in The Archive to match hashtags at the moment:
(?<=\\s|^|\\W)(?<!`)(#+[\\p{L}\\p{Nd}_\\\\+§!:;./]*[\\p{L}\\p{Nd}_\\\\+\\-§!:;./]*[\\p{L}\\p{Nd}_§]+)Note the double escape backslashes because it's part of a string. You can replace
\\\\with\\and\\with\I think.Author at Zettelkasten.de • https://christiantietze.de/
@Will:
Fantastic code- thanks for sharing!
@ctietze what exactly do you mean by "match hashtags"? What does it do?")
"Matching" is what applying a regular expression on a string is called. Wills regex is:
If you replace it with mine, you will get 100% of the tags The Archive recognizes (and makes clickable). Mine is longer, because it includes a couple of cases that are usually not included, and exludes others; also it tries to look for hashtags outside of code `...`.
Author at Zettelkasten.de • https://christiantietze.de/
Hi Will!
That looks very useful, thanks! Could you post a screenshot of the corresponding KM macro as well? I'm new to KM and don't understand fully how to incorporate your above script into a macro that does what you show.
I guess the tag list is not updated automatically, but only when you trigger the macro. Does it then delete the old tag list automatically and replace it with a new one? Or do you have to delete the old one manually first?
Thanks again!
Hi @Vinho.
This is my most useful so far note. At least the one most used as an entry point.
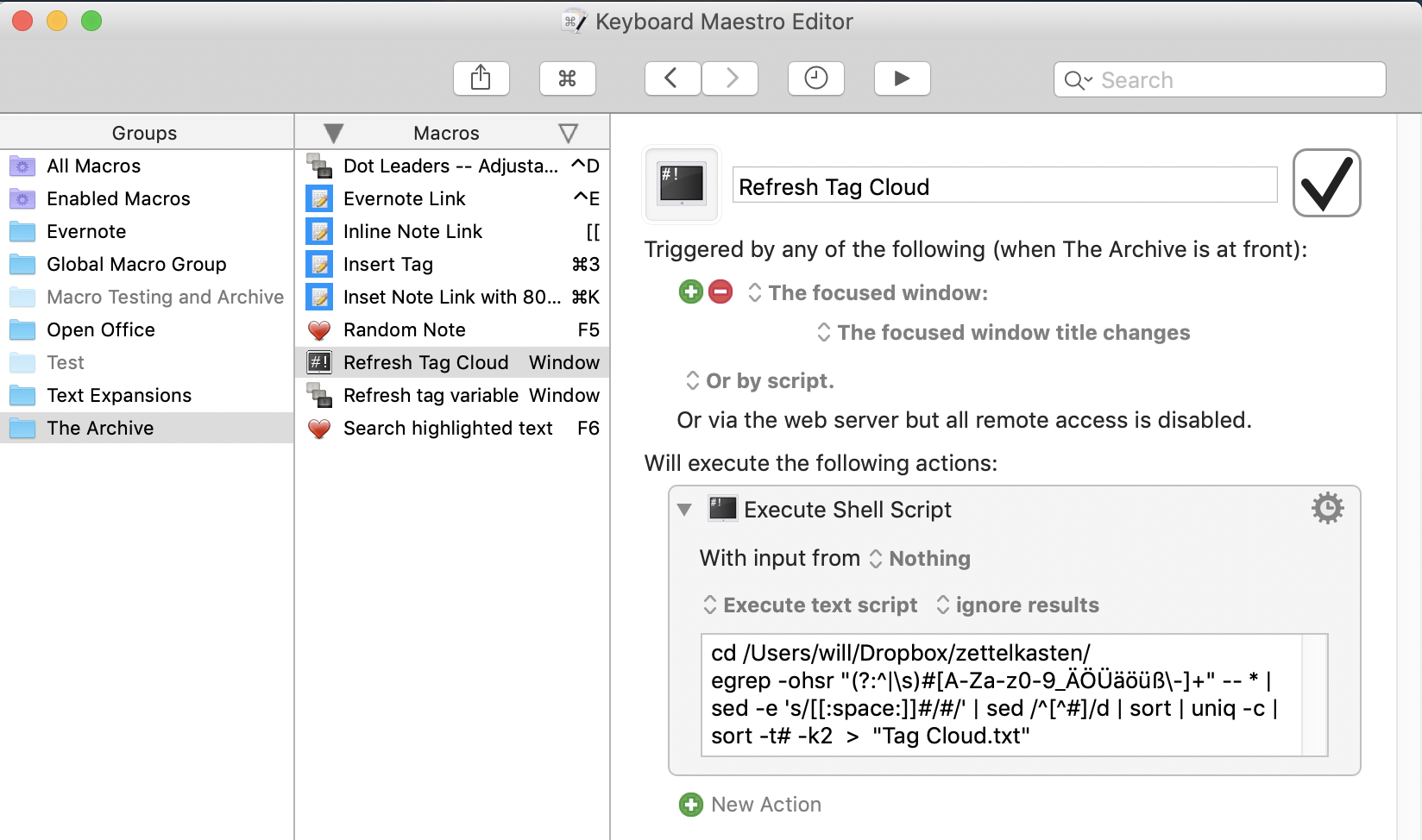
Here is a link to the macro itself. If you have Keyboard Maestro just launching the downloaded file will import it. Be sure to change the directory to your note. It is in a section in Keyboard Maestro that only runs when The Archive is active. It is automatic and overwrites the old one. It is set to launch when the "focused window changes." When I switch it another program is the macro trigger. A background activity I don't have to babysit. It is just interstitial to my workflow.
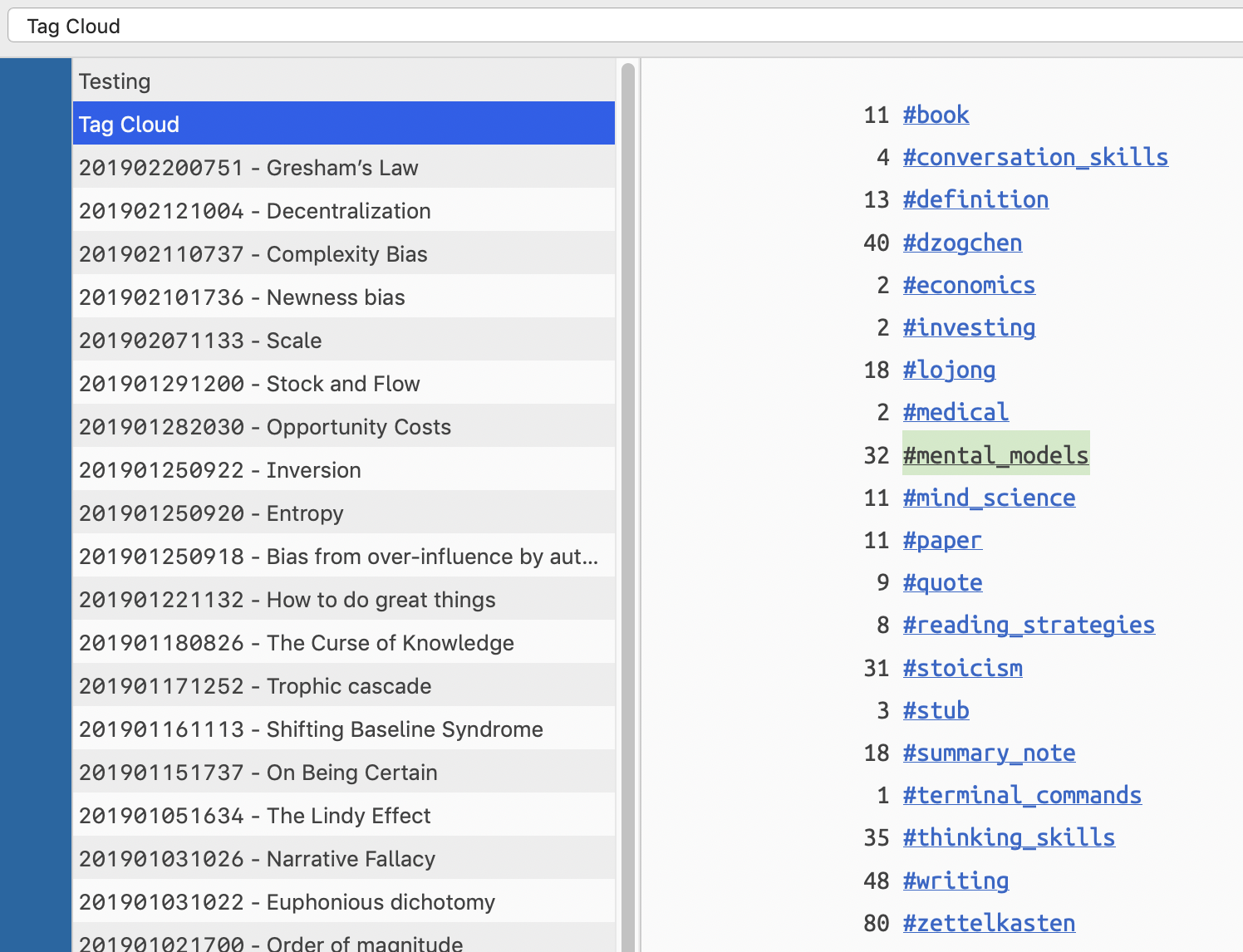
You can edit the name of the file. I called it "Tag Cloud.txt"
Also, I set the sort order in The archive to Title Z first. This put the Tag Cloud at the top, always visible.
Link to macro.
Here is a screenshot of the macro.
Here is a screenshot of the result.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
@Will: thanks for doing this. I've implemented it with Alfred (I can do that with this one!) and it works great.
One question, for whomever: would it be possible to change those
sortcommands to list the tags in order from most-to-least used?@ctietze: are you doing that regex under vanilla /bin/bash? When I try to run yours in Alfred (which is using /bin/bash), I get an error about an unmatched
\``, then when I escape the`in question, I getegrep: repetition-operator operand invalid`.@mediapathic Apparently, you need to escape the forward slash
/, too. Even then, could be thategrep's engine doesn't support all the operators.This cleaned-up pattern works in Ruby:
$ irb 2.5.1 :001> /(?<=\s|^|\W)(?<!`)(#+[\p{L}\p{Nd}_\\+§!:;.\/]*[\p{L}\p{Nd}_\\+\-§!:;.\/]*[\p{L}\p{Nd}_§]+)/ =~ "foo #bar baz" => 4Author at Zettelkasten.de • https://christiantietze.de/
Thanks a lot to Will, very helpful!
My only unfulfilled desire would be for it to find tags like
##tag, beginning with two#. I guess that's partly why @ctietze uses a different regex. I seem to have the same problem with replacing Will's regex that @mediapathic has. @ctietze: What exactly is your cleaned-up pattern for Ruby supposed to replace in Will's code?Ok, with this regex it finds tags beginning with
##:(?:^|\s)#[a-z\#][A-Za-z0-9_ÄÖÜäöüß\-]+@mediapathic your suggestion or desire to get a feeling as to the value of a note by delineating notes by "most-to-least used" is a good one and one I to wish for. This would require more than software magic. So I've implemented a manual kluge that also draws out a purposeful review of the note when encountered for work. I stole the idea from @msteffens.
He talks about it over at https://forum.zettelkasten.de/discussion/comment/2394/#Comment_2394
and shows it in a note at
https://forum.zettelkasten.de/discussion/comment/2386/#Comment_2386.
When I find myself using a note I give it a star rating. This is subjective but the exercise connects me with the value I get from the particular note. The more the note is used the more stars. Encountered a second time I add another star. A note gets no stars on creation.
I use Keyboard Maestro to do a quick text replacement to get the ★'s. I can only get them to be black in The Archive, sure would be nice if I could get them to be red or blue or yellow or any other color.
This sorting notes by value is a really hard thing.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
The first regex, i.e. the")
XXXpart inegrep -ohsr "XXX" -- * | sed .... Alas, it doesn't work out of the box for some reason, so y'all have to tinker with that if you want to have exact hashtag matching parity with The ArchiveAuthor at Zettelkasten.de • https://christiantietze.de/
Oh, I actually meant something else; I was trying to get the generated tag list to have the tags that are most used at the top, because, by definition, those are the ones I'm going to click most often.
@mediapathic please could you explain how you got this script to run in Alfred. I'm new to all but Alfred's basic functions, and am having no luck with this so far.
The following script should work (borrowed various bits from earlier messages):
-print0 puts a
\nulafter each filename.xargs -0expects filenames followed by\nul. Since a\nulis never a valid file name character, this captures all valid filenames. Option-not -name '.*'removes dot files. The-noption to the lastsortsays to do a numeric sort (so that with-rn10 comes before 9).If you cut-n-paste the above script, make sure that the ascii quote (') is not replaced with a fancy quote (what some editors do)!
@bvs, it looks like the part for filtering out dot files does not work: When I ran the script, it gave me a " #tag1" and a " #tag2" among the results, which none of my The Archive notes contain. I then realized those tags were contained in a ".saved_searches.zks" file that some other program had created that I had tried at some point.
After a bit of tinkering, I realized that the order of the parameters of the find command weirdly does matter. When I moved the
-print0parameter to the end of the find statement, the dot files were properly filtered out.So the fixed command is:
find . -type f -not -name '.*' -print0 | xargs -0 grep -EIoh '(?:^|\s)#[A-Za-z0-9_ÄÖÜäöüß\-]+' |sort | uniq -c | sort -rnEDIT:
I just realized that this is not a new thread, and that a similar command was posted by the OP. Does this new version have any advantages over the original one?
If you like The Archive's "PrettyFunctional (Basic)" theme, consider upgrading to the "PrettyFunctional (Regular)" theme.
Sorry about the order of parameters bug! This script is only a minor tweak over earlier versions. Mainly allows spaces or other chars in file names + a sorting issue.
Thank you @bvs & @Basil
@bvs @Basil thanks for taking care of @DavidWJ while I was offline for a bit there!
This is so useful - thank you.
It's highlighted something for me, though - I've not be disciplined about using all lower case when creating tags. I discover I have a lot of replicated tags - those that are all lower case and the same tags that I typed starting with a capital. Which would be less of a bother were they to be alphabetically listed (such that #ethics and #Ethics displayed together), but my list is sorted such that all the capitalised tags are listed in alphabetical order followed followed by an alphabetical list of the lower case ones.
Since changing them all (is there a global search and replace? I can only find it at the zettel level) seems unappealing, does anyone know how to change this such that it ignores the case as part of the search or, failing that, displays them properly alphabetically ignoring the case?
@JKF - I've had great success doing this sort of thing, with a global search and replace tool called MassReplaceIt. #Ethics changed to #ethics, case sensitive, in all files in /Dropbox/zettelkasten. Works perfectly and quickly. Is freeware.
Will Simpson
My peak cognition is behind me. One day soon, I will read my last book, write my last note, eat my last meal, and kiss my sweetie for the last time.
My Internet Home — My Now Page
Fantastic - that's fixed it! Thank you!
Hi there, and thanks so much for this! I'm aware that this would be useless for some people, but can anyone help a regex newbie (me) understand the regex I would need to produce a similar file for [[links]] as oppose to #tags? I'd love to see at a glance how often I have created connections to various notes.
Thanks in advance to any who can help!
I've been trying this:
and it's pulling in some numbers with preceding spaces I wasn't expecting, e.g.
(snip)
Any ideas why this might be happening? I don't think I even have 513 notes!